Raspagem de dados na web com Python e Beautiful Soup
Tempo de leitura: 4 minutos
October 22, 2019
Escrito por

A Internet tem uma variedade incrível de informações para o consumo humano, mas estes dados geralmente são difíceis de serem acessados programaticamente se não vierem na forma de uma API REST dedicada. Com ferramentas para Python como a Beaultiful Soup, você pode fazer a raspagem e tratamento desses dados diretamente das páginas web para usar em seus projetos e aplicações.
Como exemplo, faremos a raspagem de arquivos MIDI da Internet para treinar uma rede neural com Magenta, para gerar música e sons clássicos do Nintendo. Para fazer isso, vamos precisar de um conjunto de músicas MIDI de jogos antigos da Nintendo. Usando o Beaultiful Soup, podemos pegar estes dados do Arquivo de Músicas de Video Game.
Primeiros passos e configuração das dependências
Antes de continuarmos, você vai precisar se certificar de que tem uma versão atualizada do Python 3 e do pip instalado. Certifique-se de que está criando e ativando um ambiente virtual antes de instalar qualquer dependência.
Você vai precisar instalar a biblioteca Requests para fazer chamadas HTTP para pegar os dados da página Web e Beautiful Soup para tratar o HTML.
Com nosso ambiente virtual ativado, rode o comando em seu terminal:
Estamos usando o Beautiful Soup 4 porque é sua versão mais atualizada e o Beautiful Soup 3 não é mais desenvolvido nem suportado.
Usando o Requests para fazer o Scrap de dados para o Beautiful Soup parsear
Primeiro vamos escrever um pouco de código para carregar o HTML da página web e ver como podemos tratá-lo. O código a seguir vai fazer uma chamada GET para a página web que queremos e criar um objeto BeautifulSoup com o HTML da página.
Com este objeto soup, você pode navegar e procurar pelo HTML por dados que você quiser. Por exemplo, se você rodar soup.title depois do código acima em um terminal Python, você vai pegar o título da página web. Se você rodar print(soup.get_text()), você vai ver todo o texto da página.
Se familiarizando com o Beautiful Soup
Os métodos find() e find_all() estão entre as armas mais poderosas em seu arsenal. soup.find() é ótimo para casos onde você sabe que existe um elemento do qual você está procurando, como a tag de body. Nesta página, soup.find(id=’banner_ad’).text vai te trazer o texto do elemento HTML do banner de propagandas.
soup.find_all() é o método mais comum que você vai usar em suas aventuras de raspagem de dados. Usando isso, você pode iterar através de todos os hyperlinks da página e imprimir suas URLs:
Você também pode fornecer diferentes argumentos para find_all, como expressões regulares ou atributos de tags para filtrar sua busca. Você pode encontrar várias funcionalidades legais na documentação.
Parseando e navegando pelo HTML com BeautifulSoup
Antes de escrever mais código para tratar o conteúdo que queremos, vamos antes dar uma olhada no HTML que está renderizado no browser. Cada página web é diferente, e às vezes, para pegar os dados corretos, precisamos de um pouco de criatividade, reconhecimento de padrões e experimentação.
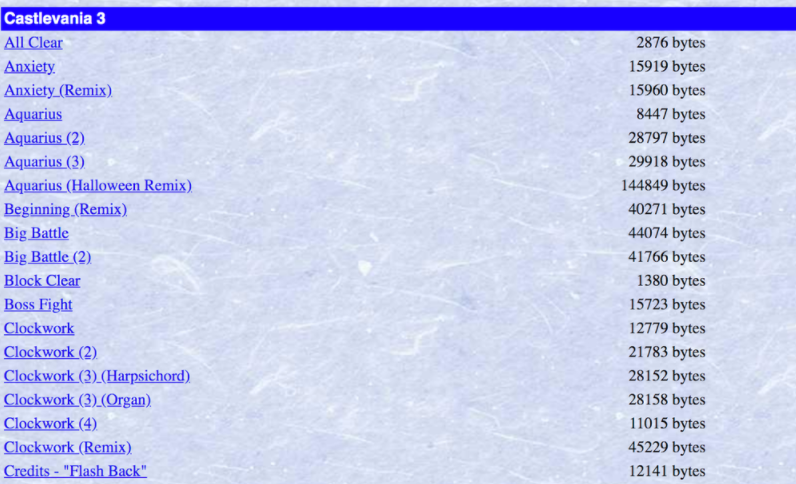
Nosso objetivo é o de fazer o download de vários arquivos MIDI, mas existem várias faixas duplicadas nesta página, assim como o Remix de várias músicas. Apenas queremos um arquivo de cada música, e porque queremos usar esses dados para treinar uma rede neural a gerar música da Nintendo de forma eficaz, não queremos treiná-las em remixes criados por pessoas.
Quando você estiver escrevendo código para parsear a página web, geralmente é útil usar o developer tools, disponível na maioria dos navegadores modernos. Se você clicar com o botão direito no elemento do qual você está interessado, você pode inspecionar o HTML por trás daquele elemento para descobrir como você pode acessar programaticamente os dados que você quiser.

Vamos usar o find_all() para passar por todos os links na página, porém usaremos expressões regulares para filtrá-los para que peguemos somente os arquivos MIDI cujo texto não tenha parênteses, o que vai nos permitir excluir todas as duplicatas e remixes.
Crie um arquivo chamado de nes_midi_scraper.py e adicione o seguinte código à ele:
Este filtro vai passar por todos os arquivos MIDI que queremos na página, imprimir a tag do link correspondente e depois imprimir quantos arquivos filtramos.
Rode o código em seu terminal com o comando python nes_midi_scraper.py.
Baixando os arquivos MIDI que queremos da página web
Agora que temos nosso código percorrendo os arquivos MIDI que queremos, precisamos escrever código para baixar todos eles.
No nes_midi_scraper.py, adicione uma função ao seu código chamada de download_track e chame esta função para cada faixa no loop:
Nesta função download_track, estamos passando o objeto BeautifulSoup representando os elementos HTML do link para o arquivo MIDI, junto com um número único para usar como nome de arquivo para evitar possíveis colisões de nomes.
Rode este código de um diretório onde você queira salvar todos os arquivos MIDI, e veja sua tela de terminal mostrar todos os a 2230 arquivos MIDI que você baixou (no momento em que estamos escrevendo este texto). Este é apenas um exemplo prático do que você pode fazer com o Beautiful Soup.
A vasta expansão da World Wide Web
Agora que você pode programaticamente pegar coisas das páginas web, você tem acesso a uma enorme fonte de dados para qualquer projeto que precisar. Uma coisa para se manter em mente é a de que mudanças no HTML de páginas web podem quebrar o seu código, então garanta que você está mantendo tudo atualizado se estiver construindo aplicações em cima disso.
Se você estiver procurando algo para fazer com o dado que acabamos de pegar do Arquivo de Músicas de Videogame, tente usar as bibliotecas Python como Mido para trabalhar com os dados MIDI para limpá-los, ou use Magenta para treinar uma rede neural, ou se divirta construindo um número de telefone da qual pessoas podem ligar para ouvir músicas da Nintendo.
Estou ansioso para ver o que você vai construir. Sinta-se à vontade para entrar em contato, compartilhar experiências ou fazer perguntas através do e-mail lleao@twilio.com.


Recursos relacionados
Twilio Docs
De APIs a SDKs e aplicativos de amostra
Documentação de referência de API, SDKs, bibliotecas auxiliares, guias de início rápido e tutoriais para sua linguagem e plataforma.
Centro de Recursos
Os mais recentes e-books, relatórios do setor e webinars
Aprenda com especialistas em engajamento do cliente para melhorar sua própria comunicação.
Ahoy
Centro da comunidade de desenvolvedores da Twilio
Melhores práticas, exemplos de código e inspiração para criar comunicações e experiências de engajamento digital.