O guia definitivo para o modelo de linguagem GPT-3 da OpenAI
Tempo de leitura: 22 minutos
August 25, 2020
Escrito por
Revisado por

O Transformador Generativo Pré-Treinado 3 (GPT-3) é um novo modelo de linguagem criado pela OpenAI que é capaz de gerar texto escrito com tamanha qualidade que muitas vezes é difícil distinguir do texto escrito por um humano.
Neste artigo, vamos explorar como trabalhar com o GPT-3 para vários casos de uso, desde como usá-lo como assistente de escrita até a construção de um chatbot altamente sofisticado. No final, você saberá como programar o GPT-3 para conversar com você sobre seus tópicos favoritos. Aqui está um exemplo de uma conversa curta que tive com o bot sobre Python e desenvolvimento Web.

É tão bom assim?
Você acha difícil acreditar que o GPT-3 pode gerar texto que é praticamente indistinguível do que um escritor humano pode produzir? Vou deixar que você julgue por si mesmo com outro exemplo.
Os dois parágrafos a seguir foram gerados pelo mecanismo GPT-3 para se descrever, depois que eu o treinei apenas mostrando o primeiro parágrafo do artigo sobre GPT-3 no Wikipedia. Observe que estou copiando o texto a seguir literalmente, isso foi exatamente o que o GPT-3 produziu sem edição.
GPT-3 é uma rede neural profunda que usa o mecanismo de atenção para prever a próxima palavra em uma frase. Ele é treinado em um corpus de mais de 1 bilhão de palavras e pode gerar texto com precisão no nível dos caracteres. A arquitetura do GPT-3 consiste em dois componentes principais: um codificador e um decodificador. O codificador recebe como entrada a palavra anterior na frase e produz uma representação vetorial dela, que é então passada por um mecanismo de atenção para produzir a previsão da próxima palavra. O decodificador assume como entrada a palavra anterior e sua representação vetorial e gera uma distribuição de probabilidade sobre todas as palavras possíveis dadas essas entradas.
O desempenho do GPT-3 está no mesmo nível dos melhores modelos de linguagem para geração de texto, o que é significativamente melhor do que os modelos do GPT anteriores. O modelo Turing NLG da Microsoft pode gerar texto com precisão no nível de caracteres em um conjunto de testes de artigos da Wikipédia, mas requer uma enorme quantidade de dados de treinamento para isso. A OpenAI afirma que o GPT-3 pode atingir esse nível de desempenho sem nenhum dado de treinamento adicional após seu período inicial de pré-treinamento. Além disso, o GPT-3 é capaz de gerar frases e parágrafos mais longos do que os modelos anteriores, como BERT da Google e Transformer da Stanford NLP.
Impressionante, não é?
O que vamos desenvolver
Vamos aprender como trabalhar com o OpenAI Playground, uma interface baseada na Web que, como o nome sugere, permite que você brinque e crie protótipos de soluções baseadas no GPT-3.
Não vamos desenvolver um único projeto específico. Em vez disso, implementaremos alguns protótipos diferentes para uma série de problemas diferentes.
No final, também veremos como transferir o trabalho que você fez no Playground para um aplicativo Python autônomo.
Pré-requisitos
Para acompanhar os exemplos apresentados neste tutorial, o único requisito é ter uma licença do OpenAI GPT-3. No momento em que escrevo isso, o OpenAI está executando um programa beta para o GPT-3, e você pode solicitar uma licença beta diretamente a eles.
Se você estiver interessado em escrever aplicativos GPT-3 autônomos em Python, também precisará ter o Python 3.6 ou superior instalado. Isso é totalmente opcional, você pode ignorar a seção Python se não estiver interessado nela.
O OpenAI Playground
Eu mencionei acima que eu tive que "treinar" o GPT-3 produzir a saída de texto desejada. Isso é surpreendentemente fácil e pode ser feito no OpenAI Playground. Abaixo, você pode ver uma imagem da instância do Playground na qual eu gerei o texto mostrado acima:
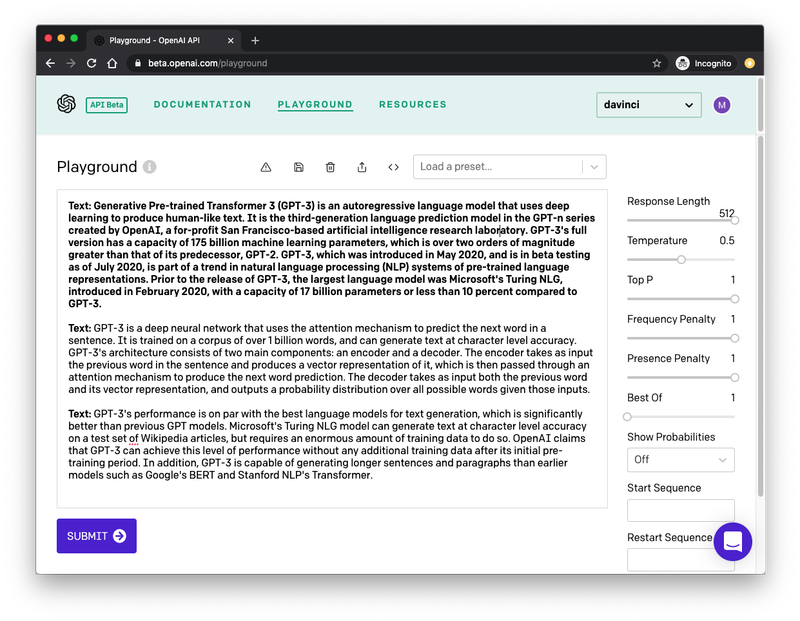
Vou explicar os principais aspectos dessa interface.
A barra lateral à direita tem algumas opções para configurar o tipo de saída que esperamos que o GPT-3 produza. Mais adiante neste artigo, vamos ver essas configurações em detalhes.
A grande área de texto é onde você interage com o mecanismo GPT-3. O primeiro parágrafo, que aparece em negrito é o que o GPT-3 receberá como entrada. Comecei este parágrafo com o prefixo Text: e, em seguida, colei o texto que eu copiei de um artigo da Wikipédia. Este é o aspecto principal do treinamento do motor: você o ensina com exemplos, sobre qual tipo de texto pretende que ele gere. Em muitos casos, um único exemplo é suficiente, mas você pode fornecer mais.
O segundo parágrafo começa com o mesmo prefixo Text:, que também aparece em negrito. Essa segunda aparência do prefixo é a última parte da entrada. Estamos fornecendo ao GPT-3 um parágrafo que tem o prefixo e um exemplo de texto, seguido por uma linha que só tem o prefixo. Isso dá ao GPT-3 a indicação de que ele precisa gerar algum texto para completar o segundo parágrafo de modo que ele corresponda ao primeiro em tom e estilo.
Depois de definir o texto de treinamento e as opções de acordo com sua preferência, pressione o botão "Submit" (Enviar) na parte inferior e o GPT-3 vai analisar o texto de entrada e gerar mais alguns para corresponder. Se você pressionar "Submit" (Enviar) novamente, o GPT-3 será executado novamente e produzirá outro bloco de texto.
Tudo o que fiz para gerar os dois parágrafos acima foi criar o texto inserido e pressionar o botão "Submit" (Enviar) duas vezes!
Trabalhar com predefinições do GPT-3
OK, vamos começar! Faça login no OpenAI Playground para se familiarizar com a interface.
No canto superior direito da barra de navegação, há uma lista suspensa para selecionar um dos vários modelos de idioma:
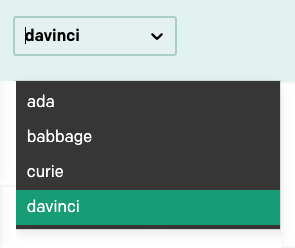
Neste tutorial, vamos usar apenas o modelo davinci, que é o mais avançado neste momento, portanto, certifique-se de que ele seja o modelo selecionado. Depois de aprender a trabalhar com o Playground, você pode alternar para os outros modelos e fazer experiências com eles também.
Acima da área de texto há outro menu suspenso com o rótulo "Load a preset…" (Carregar uma predefinição…).
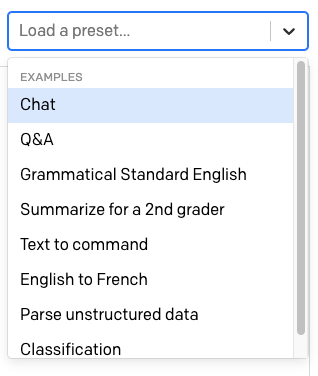
Aqui, o OpenAI fornece várias predefinições prontas para serem usadas para diferentes situações do GPT-3.
Selecione a predefinição "English to French" (Inglês para francês). Quando você escolhe uma predefinição, o conteúdo da área de texto é atualizado com um texto de treinamento predefinido para ela. As configurações na barra lateral direita também são atualizadas.
No caso do modelo "English to French" (Inglês para francês), o texto apresenta algumas frases em inglês, cada uma com a sua tradução em francês:

Como no meu próprio exemplo acima, cada linha é iniciada com um prefixo. Como esse aplicativo tem linhas em inglês e em francês, o prefixo é diferente para ajudar o GPT-3 a entender o padrão.
Observe como, na parte inferior do texto, há um prefixo English: vazio. Aqui é onde podemos inserir o texto que gostaríamos que o GPT-3 traduzisse para o francês. Vá em frente e digite uma frase em inglês e pressione o botão "Submit" (Enviar) para que o GPT-3 gere a tradução para o francês. Aqui está o exemplo que eu usei:

A predefinição adiciona outro prompt English: vazio para você, então você pode digitar diretamente a próxima frase que deseja traduzir.
Todas as predefinições fornecidas pelo OpenAI são fáceis de usar e autoexplicativas, portanto, neste momento, seria uma boa ideia jogar com outras pessoas. Em particular, recomendo as predefinições "Q&A" (Perguntas e respostas) e "Summarize for a 2nd grader" (Resumir para um segundo ano).
Criar seus próprios aplicativos GPT-3
Embora as predefinições fornecidas pelo OpenAI Playground sejam divertidas de brincar, você certamente terá suas próprias ideias para usar o mecanismo GPT-3. Nesta seção, veremos todas as opções fornecidas no Playground para criar seus próprios aplicativos.
Criar sua própria solução baseada em GPT-3 envolve escrever o texto de entrada para treinar o mecanismo e ajustar as configurações na barra lateral de acordo com suas necessidades.
Para acompanhar os exemplos nesta seção, certifique-se de restaurar as configurações padrão do Playground. Para fazer isso, exclua todo o texto da área de texto e, se tiver uma predefinição selecionada, clique no "x" ao lado do nome para removê-lo.

Temperatura
Uma das definições mais importantes para controlar a saída do motor do GPT-3 é a temperatura. Essa configuração controla a aleatoriedade do texto gerado. Um valor 0 torna o mecanismo determinístico, o que significa que ele sempre gerará a mesma saída para um determinado texto de entrada. O valor 1 faz com que o motor assuma o maior risco e use muita criatividade.
Gosto de começar a criar protótipos de um aplicativo definindo a temperatura para 0, então vamos começar fazendo isso. O parâmetro "Top P" que aparece abaixo da temperatura também tem algum controle sobre a aleatoriedade da resposta, portanto, certifique-se de que ele esteja no valor padrão de 1. Deixe todos os outros parâmetros também em seus valores padrão.
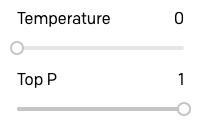
Com essa configuração, o GPT-3 se comportará de maneira muito previsível, portanto, esse é um bom ponto de partida para testar as coisas.
Agora você pode digitar um texto e pressionar "Submit" (Enviar) para ver como o GPT-3 adiciona algo mais. No exemplo abaixo, digitei o texto Python is deixe GPT-3 completar a sentença.

Isso é incrível, certo?
Antes de continuarmos, esteja ciente de que o GPT-3 não gosta de strings de entrada que terminam em um espaço, pois isso causa comportamentos estranhos e, às vezes, imprevisíveis. Você pode querer adicionar um espaço após a última palavra de sua entrada, portanto, lembre-se de que isso pode causar problemas. O Playground mostrará um aviso se, por engano, você deixar um ou mais espaços no final da sua entrada.
Agora aumente a temperatura para 0,5. Exclua o texto gerado acima, deixando mais uma vez apenas Python is e clique em "Submit" (Enviar). Agora, o GPT-3 vai ficar mais criativo quando completar a sentença. Aqui está o resultado:

Ao tentar isso, você provavelmente terá algo diferente. E se você tentar isso várias vezes, sempre obterá um resultado diferente.
Sinta-se à vontade para experimentar diferentes valores de temperatura para ver como o GPT-3 se torna mais ou menos criativo com suas respostas. Quando estiver pronto para continuar, defina a temperatura novamente para 0 e execute novamente a solicitação original Python is.
Tamanho da resposta
As conclusões de texto na seção anterior foram realmente boas, mas você provavelmente percebeu que o GPT-3 geralmente para no meio de uma frase. Para controlar a quantidade de texto gerado, você pode usar a configuração "Response Length" (tamanho da resposta).
A configuração padrão para o tamanho da resposta é 64, o que significa que GPT-3 adicionará 64 tokens ao texto, com um token sendo definido como uma palavra ou um sinal de pontuação.
Tendo a resposta original à entrada Python is com a temperatura definida como 0 e um tamanho de 64 tokens, você pode pressionar o botão "Submit" (Enviar) uma segunda vez para que o GPT-3 acrescente outro conjunto de 64 tokens adicionados ao final.

Mas é claro que, mais uma vez, ficamos com uma frase incompleta no final. Um truque simples que você pode usar é definir o tamanho para um valor maior do que o que você precisa e, em seguida, descartar a parte incompleta no final. Veremos mais tarde como ensinar o GPT-3 a parar no lugar certo.
Prefixos
Você viu que quando eu gerei os dois parágrafos da demonstração perto do início deste artigo eu prefixei cada parágrafo com um prefixo Text:. Você também viu que a predefinição de tradução de inglês para francês usou os prefixos English: e French: nas linhas correspondentes.
Usar um prefixo curto para cada linha de texto é uma ferramenta muito útil para ajudar o GPT-3 a entender melhor qual resposta é esperada. Considere um aplicativo simples no qual queremos que o GPT-3 gere nomes de variáveis metassintáticas que podemos usar ao escrever o código. Essas são variáveis de espaço reservado, como foo e bar, geralmente usadas em exemplos de codificação.
Podemos treinar o GPT-3 mostrando uma dessas variáveis e permitindo que ele gere mais. Seguindo o exemplo anterior, podemos usar foo como entrada, mas desta vez vamos pressionar enter e mover o cursor para uma nova linha, para dizer ao GPT-3 que queremos a resposta na próxima linha. Infelizmente, isso não funciona bem, pois o GPT-3 não "obtém" o que queremos:

O problema aqui é que não estamos dizendo claramente para o GPT-3 que o que queremos é ter mais linhas como a que inserimos.
Vamos tentar adicionar um prefixo para ver como isso melhora nosso treinamento. O que vamos fazer é usar var: foo como a nossa entrada, mas também forçaremos o GPT-3 a seguir o nosso padrão digitando var: na segunda linha. Uma vez que a segunda linha está agora incompleta quando comparada com a primeira, estamos tornando mais claro que queremos que "algo como o foo" seja adicionado.
E isso funciona muito melhor:

Sequências de interrupção
Em todos os exemplos que tentamos temos o problema de que o GPT-3 gera um fluxo de texto até o tamanho solicitado e, em seguida, ele para, muitas vezes no meio de uma frase. A opção "Stop Sequences" (Sequências de interrupção), que pode ser encontrada na parte inferior da barra lateral direita, permite definir uma ou mais sequências que, quando geradas, forçam o GPT-3 a parar.
Seguindo o exemplo da seção anterior, digamos que gostaríamos de ter apenas uma nova variável cada vez que invocamos o motor do GPT-3. Como estamos prefixando cada linha com var: e estamos preparando o motor inserindo o prefixo sozinho na última linha da entrada, podemos usar esse mesmo prefixo como uma sequência de interrupção.
Encontre o campo "Stop Sequences" (Sequências de interrupção) na barra lateral e digite var: seguido por Tab.
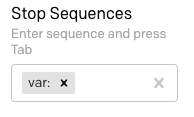
Agora redefina o texto de entrada para var: foo na primeira linha e apenas var: na segunda linha, e clique em "Submit" (Enviar). Agora, o resultado é uma única variável:

Digite outro var: na terceira linha do texto de entrada e envie novamente, e você receberá mais uma.

Texto inicial
Estamos fazendo progressos para fazer GPT-3 retornar as respostas que esperamos, mas nosso próximo aborrecimento é que sempre que queremos solicitar uma resposta, precisamos digitar manualmente o prefixo para que a linha GPT-3 precise ser concluída.
A opção "Inject Start Text" (Incluir texto de início) nas configurações informa ao Playground qual texto deve ser anexado automaticamente à entrada antes de enviar uma solicitação para GPT-3. Coloque o cursor neste campo e digite var:.

Agora redefina o texto para uma única linha de texto com var: foo. Pressione enter para que o cursor seja exibido no início da segunda linha e pressione "Submit" (Enviar) para ver a próxima variável. Cada vez que você enviar, receberá um novo, com os prefixos inseridos automaticamente.

Usar vários prefixos
O gerador de nomes de variáveis que usamos nas últimas seções segue a abordagem simples de mostrar ao GPT-3 uma amostra de texto para obter mais semelhantes. Usei este mesmo método para gerar os dois parágrafos do texto que apresentei no início deste artigo.
Outro método de interação com GPT-3 é fazer com que ele aplique algum tipo de análise e transformação ao texto de entrada para produzir a resposta. Até agora, só vimos a predefinição de tradução do inglês para o francês como um exemplo desse tipo de interação. Outras possibilidades são chatbots de perguntas e respostas, com erros gramaticais corretos de GPT-3 no texto de entrada e ainda mais esotéricos, como converter instruções de design fornecidas em inglês em HTML.
A característica interessante desses projetos é que há um diálogo entre o usuário e o GPT-3, e isso requer o uso de dois prefixos para marcar separadamente as linhas que pertencem ao usuário e ao GPT-3.
Para demonstrar esse tipo de estilo de projeto, vamos criar um bot ELI5 (explique como eu sou 5) que aceitará um conceito complexo do usuário e retornará uma explicação dele usando palavras simples que uma criança de cinco anos possa entender.
Redefina seu Playground de volta ao estado inicial padrão clicando no ícone de lixeira.

Para criar o bot ELI5, vamos mostrar ao GPT-3 um exemplo de interação. A linha que mostra o que queremos explicar vai usar o prefixo thing:, enquanto a linha com a explicação vai usar eli5:. Veja como podemos treinar o GPT-3 nesta tarefa usando "microfone" como nosso exemplo de treinamento:

Fácil, certo? Temos que usar palavras simples na resposta do treinamento, porque queremos que o GPT-3 gere outras respostas em um estilo semelhante.
A opção "Inject Start Text" (Incluir texto de início) pode ser definida como [enter]eli5:, de modo que o Playground adicione automaticamente o prefixo para a linha GPT-3.

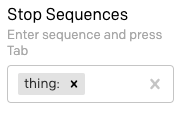
Também precisamos definir uma sequência de interrupção, para que o GPT-3 saiba quando parar. Podemos usar thing: aqui, para garantir que o GPT-3 entenda que as linhas "thing" não precisam ser geradas. Lembre-se de que, neste campo, você deve pressionar a tecla Tab para concluir a entrada da sequência de interrupção.
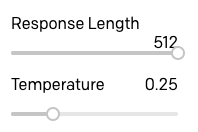
Defini o tamanho de resposta para o máximo de 512, pois a sequência de interrupção é a forma que usamos para fazer o GPT-3 parar. Também movi o controle deslizante de temperatura para 0,25, para que as respostas não sejam muito embelezadas ou aleatórias, mas esta é uma área onde você pode jogar com diferentes configurações e encontrar o que funciona melhor para você.
Pronto para experimentar nosso bot ELI5? Esta é a primeira tentativa:

Isso é muito bom, certo? Como temos a temperatura definida para um valor diferente de zero, as respostas que você obtém podem ser ligeiramente diferentes das minhas.
Reiniciar texto
Se você começou a brincar com o bot ELI5 da seção anterior, talvez tenha notado que você tem que redigitar o prefixo thing: toda vez que quiser fazer ao bot uma nova pergunta.
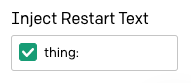
A opção "Inject Restart Text" (Incluir texto de reinício) na barra lateral pode ser usada para inserir automaticamente algum texto após a resposta GPT-3, para que possamos usá-lo para digitar automaticamente o próximo prefixo. Eu inseri o prefixo thing: seguido por um espaço aqui.
Agora é muito mais fácil jogar e interagir com o GPT-3 e fazer com que ele explique as coisas para nós!

A opção "Top P"
O argumento "Top P" é uma forma alternativa de controlar a aleatoriedade e criatividade do texto gerado pelo GPT-3. A documentação do OpenAI recomenda que somente um dos recursos Temperatura e Top P sejam usados, portanto, ao usar um deles, certifique-se de que o outro esteja definido como 1.
Eu queria experimentar e ver como as respostas do GPT-3 variavam ao usar o Top P em vez da temperatura, então eu elevei a temperatura para 1 e abaixei o Top P para 0,25:
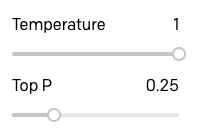
Então eu repetirei a sessão de cima.

Como podem ver, não há uma enorme diferença, mas acredito que a qualidade das respostas é um pouco mais baixa. Considere a resposta para a viagem no tempo, que é uma explicação realmente insatisfatória, e também como o GPT-3 repete o conceito de encontrar informações em duas das respostas.
Para ver se eu poderia melhorar essas respostas um pouco, aumentei o Top P até 0,5:
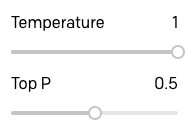
As respostas são definitivamente melhores:

Para concluir minha investigação de temperatura e Top P, tentei as mesmas consultas usando um valor de temperatura de 0,5:
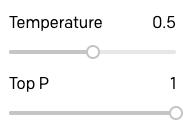
Estes são os resultados:

Claramente, para este tipo de aplicação, uma temperatura de 0,5 é um pouco maior e o GPT-3 se torna mais vago e informal em suas respostas.
Depois de jogar com vários projetos e experimentar a temperatura e o Top P, minha conclusão é que o Top P fornece melhor controle para aplicativos nos quais o GPT-3 deve gerar texto com precisão e exatidão, enquanto a temperatura funciona melhor para os aplicativos nos quais o original, respostas criativas ou mesmo divertidas são procuradas.
Para o bot ELI5, decidi que usar o Top P configurado para 0,5, pois foi o que forneceu as melhores respostas.
Predefinições personalizadas
Até agora, já brincamos com a maioria das opções de configuração, e temos uma primeira aplicação interessante, nosso bot ELI5.
Antes de avançarmos para desenvolver outro projeto, você deve salvar o bot ELI5, juntamente com as configurações que você descobriu que funcionam melhor para você.
Comece redefinindo o texto para incluir apenas a parte de treinamento com a definição de um microfone, mais o prefixo thing: na terceira linha. Depois que o texto for redefinido para o treinamento inicial, use o ícone de disquete para salvar o projeto como uma predefinição:

Para cada predefinição salva, você pode fornecer um nome e uma descrição.
Agora, a predefinição aparece na lista suspensa de predefinições e você pode chamá-la apenas selecionando-a.
Para compartilhar essa predefinição com outras pessoas, use o botão compartilhar:

Ao compartilhar uma predefinição, será oferecida uma URL que você pode divulgar para os seus amigos:
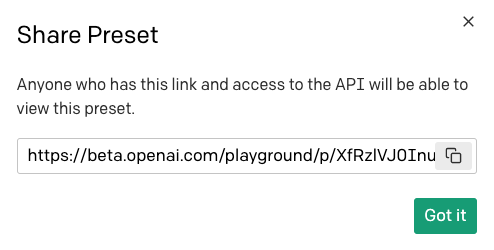
Observe que qualquer pessoa que receber esta URL precisa ter acesso ao OpenAI Playground para poder utilizar a sua predefinição.
Penalidades por frequência e presença
Vejamos mais duas das opções que ainda não exploramos. Os controles deslizantes "Frequency Penalty" (Penalidade de frequência) e "Presence Penalty" (Penalidade de presença) permitem controlar o nível de repetição que o GPT-3 pode usar em suas respostas.

A penalidade de frequência funciona diminuindo as chances de uma palavra ser selecionada novamente mais vezes do que a palavra já foi usada. A penalidade de presença não considera a frequência com que uma palavra foi usada, mas apenas se a palavra existe no texto.
A diferença entre essas duas opções é sutil, mas você pode pensar na penalidade de frequência como uma forma de evitar repetições de palavras e a penalidade de presença como uma forma de evitar repetições de tópicos.
Não tive muita sorte em entender como essas duas opções funcionam. Em geral, descobri que com essas opções definidas para seus padrões em 0, o GPT-3 provavelmente não vai se repetir devido à randomização que os parâmetros de temperatura e/ou Top P fornecem. Nas poucas situações em que eu encontrei alguma repetição, eu apenas movi ambos os controles deslizantes para 1 e isso o corrigiu.
Aqui está um exemplo em que dei ao GPT-3 uma descrição da linguagem de programação Python, que na verdade tirei de sua própria resposta e, em seguida, pedi que me desse uma descrição da linguagem JavaScript. Com as penalidades de temperatura, frequência e presença definidas como zero, foi isso que eu consegui:

Você pode ver que esta descrição não é realmente tão boa. O GPT-3 está nos dizendo que o JavaScript é uma linguagem de script e que é baseado em protótipo duas vezes cada. Com os dois parâmetros de penalidade de repetição definidos como 1, obtenho uma definição muito melhor:

A opção "Best Of"
A opção "Best Of" (melhor de) pode ser usada para que o GPT-3 gere várias respostas para uma consulta. Em seguida, o Playground seleciona a melhor e o exibe.

Eu realmente não encontrei um bom uso desta opção, porque não está claro para mim como é tomada uma decisão sobre qual das várias opções é a melhor. Além disso, ao definir essa opção para qualquer valor diferente de 1, o Playground para de mostrar as respostas à medida que são geradas em tempo real, pois precisa receber a lista completa de respostas para escolher a melhor.
Exibir probabilidades de palavras
A última opção na barra lateral de configurações é "Show Probabilities" (Mostrar probabilidades), que é uma opção de depuração que permite que você veja por que determinados tokens foram selecionados.
Carregue a predefinição ELI5 novamente. Defina "Show Probabilities" (Mostrar probabilidades) como "Most Likely" (Mais provável) e execute a inicialização com a palavra "book" (livro) mais uma vez. O texto resultante será colorido:
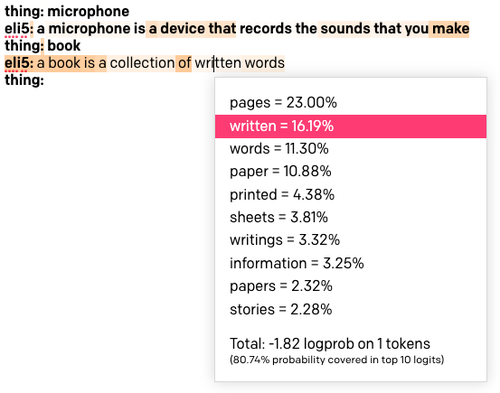
Quanto mais escuro for o plano de fundo de uma palavra, mais provavelmente essa palavra será escolhida. Se você clicar em uma palavra, verá uma lista de todas as palavras que foram consideradas nessa posição do texto. Acima, você pode ver que cliquei na palavra "written" (escrito), que tem uma cor bastante clara, e descobre que foi a segunda opção favorita depois da palavra "pages" (páginas). Esta palavra foi escolhida em vez da favorita devido à randomização das configurações de Top P e/ou temperatura.
Ao definir essa opção como "Least Likely" (Menos provável), a cor funciona em ordem inversa, com os fundos mais escuros atribuídos às palavras que foram selecionadas apesar de não ser uma opção provável.
Se você definir a opção como "Full Spectrum" (Espectro total), verá as palavras menos e mais prováveis coloridas, com tons verdes para as palavras mais prováveis e vermelhos para as menos prováveis.

Implementar um chatbot
Considerando a grande quantidade de texto que foi usada na criação do modelo de linguagem GPT-3, é possível criar bots altamente avançados que podem oferecer uma conversa aparentemente inteligente sobre vários tópicos diferentes.
Como projeto final, criaremos um chatbot de forma livre para que você possa usar para conversar com o GPT-3 sobre qualquer coisa que desejar. Aqui está um exemplo de conversa sobre Python e desenvolvimento da web que tive com este bot:

Você pode ver na imagem que o treinamento é apenas as duas primeiras linhas, em que inseri uma saudação inventada entre um humano e a IA. As palavras que eu usei aqui são informais, porque eu queria que o bot fosse divertido e interessante para conversar. Se quisesse criar um chatbot mais "sério", teria de ajustar estas linhas de acordo.
Redefina seu Playground de volta aos padrões e insira as duas primeiras linhas acima, ou as iguais às que você gosta. Na terceira linha, adicione o prefixo Human:, deixando-o pronto para que possamos inserir o texto.
Abaixo a configuração que eu usei:
- Response Length (Tamanho da resposta): 512
- Temperature (Temperatura): 0,9
- Top P: 1
- Frequency Penalty (Penalidade de frequência): 1
- Presence Penalty (Penalidade de presença): 1
- Best Of: 1
- Show Probabilities (Exibir probabilidades): Off (desativado)
- Inject Start Text (Incluir texto de início):
↵AI: - Inject Restart Text (Incluir texto de reinício):
↵Human: - Stop Sequences (Parar as sequências):
↵Human:e↵
A maioria das configurações acima deve ser clara com base nos exemplos da seção anterior, mas esta é a primeira vez que usei mais de uma sequência de interrupção. Ao usar altos níveis de randomização, seja com temperatura ou Top P, descobri que o GPT-3 às vezes responde gerando vários parágrafos. Para evitar que o chat receba respostas de vários parágrafos muito grandes e confusas, adicionei um caractere de nova linha como uma segunda sequência de interrupção, de modo que sempre que o GPT-3 tentar ir para um novo parágrafo, a sequência de interrupção faça com que a resposta termine lá.
Tente conversar com o bot sobre qualquer tópico que você goste, mas lembre-se de que, neste momento, o modelo de linguagem não conhece os eventos atuais porque seu conjunto de treinamento não inclui dados posteriores a outubro de 2019. Por exemplo, embora eu tenha achado o bot muito bem informado sobre o coronavírus em geral, ele não sabe nada da pandemia da COVID-19.
Depois de chegar às configurações que você mais gosta, redefina o texto de volta para o treinamento inicial e salve o chat como uma predefinição. Na próxima seção, vamos transferir esse chat para Python.
Migrar do Playground para Python
O OpenAI disponibilizou um pacote Python para interagir com o GPT-3, de modo que a tarefa de portabilidade de um aplicativo do Playground não é complicada.
Para seguir esta parte do tutorial, você precisa ter o Python 3.6 ou mais recente instalado em seu computador. Vamos começar criando um diretório de projetos onde criaremos nosso projeto Python:
Para este projeto, usaremos as melhores práticas do Python, então vamos criar um ambiente virtual onde vamos instalar o pacote OpenAI. Se você estiver usando um sistema Unix ou MacOS, digite os seguintes comandos:
Se você estiver seguindo o tutorial no Windows, digite os seguintes comandos em uma janela do prompt de comando:
Enviar uma consulta GPT-3
O código necessário para enviar uma consulta ao mecanismo GPT-3 pode ser obtido diretamente do Playground. Selecione a predefinição salva para o chat salvo anteriormente ou sua predefinição favorita e clique no botão "Export Code" (Exportar código) na barra de ferramentas:

Agora você verá um pop-up que mostra um fragmento Python que pode ser copiado para a área de transferência. Este é o código que foi gerado para minha predefinição de chat:
Embora isso seja realmente muito útil e possa nos ajudar na maior parte do caminho, há algumas coisas a serem observadas.
As opções "Inject Start Text" (Incluir texto de início) e "Inject Restart Text" (Incluir texto de reinício) são definidas como as variáveis start_sequence e restart_sequence, mas não são usadas na chamada de API real. Isso ocorre porque essas opções do Playground não existem na API OpenAI e são implementadas diretamente pela página da web do Playground, então precisaremos replicar suas funcionalidades diretamente no Python.
Além disso, vimos como podemos executar várias interações com o GPT-3 consecutivas, onde cada nova consulta inclui os prompts e as respostas dos anteriores. Esse acúmulo de conteúdo também é implementado pelo Playground e precisa ser replicado com lógica Python.
Usando o trecho acima do código Python como base, criei uma função gpt3() que imita o comportamento do Playground. Copie o código abaixo para um arquivo chamado gpt3.py:
Em primeiro lugar, neste código, estou importando a chave OpenAI de uma variável de ambiente, pois isso é mais seguro do que adicionar sua chave diretamente no código, como sugerido pelo OpenAI.
A função gpt3() usa todos os argumentos que vimos antes que definem como executar uma consulta GPT-3. O único argumento necessário é prompt, que é o texto real da consulta. Para todos os outros argumentos, adicionei padrões que correspondem ao Playground.
Dentro da função, execute uma solicitação GPT-3 usando um código semelhante ao trecho sugerido. Para o prompt, anexei o texto inicial passado, para duplicar a conveniência de não ter que adicionar manualmente o que conseguimos do Playground.
A resposta do GPT-3 é um objeto que tem a seguinte estrutura:
A partir desses dados, estamos interessados apenas no texto real da resposta, então usei a expressão response.choices[0].text para recuperá-la. A razão pela qual choices é retornada como uma lista é que há uma opção na API OpenAI para solicitar várias respostas a uma consulta. Isso é realmente usado pela configuração "Best Of" no Playground. Não estamos usando essa opção, então a lista choices sempre terá uma única entrada para nós.
Depois de colocar o texto da resposta na variável answer, crio um novo prompt que inclui o prompt original concatenado com a resposta e o texto de reinicialização, exatamente como o Playground faz. O objetivo de gerar um novo prompt é retorná-lo ao autor da chamada para que ele possa ser usado em uma chamada de acompanhamento. A função gpt3() retorna a resposta autônoma e o novo prompt.
Observe que não usei todos os recursos da API neste código. A Documentação da API OpenAI é a melhor referência para saber mais sobre todas as funcionalidades disponíveis, por isso, certifique-se de verificar isso caso encontre algo útil para o seu projeto.
Criar uma função de chat
Com o suporte da função gpt3() da seção anterior, agora podemos criar um aplicativo de chat. Coloque o seguinte código em um arquivo chamado chat.py:
A única dependência usada por este aplicativo é a função gpt3() da seção anterior, que importamos na parte superior.
A função chat() cria uma variável prompt que é atribuída à troca composta que treina o GPT-3 na estrutura do chat. Em seguida, entramos no loop de bate-papo, que começa pedindo ao usuário para digitar sua mensagem usando a função input() do Python. A mensagem do usuário é anexada ao prompt e então gpt3() é chamado com o prompt e as definições de configuração desejadas. A função gpt3() retorna uma resposta e o prompt atualizado. Nós mostramos ao usuário a resposta e, na próxima iteração do loop, vamos repetir o ciclo, desta vez usando um prompt atualizado que inclui a última interação.
O chat termina quando o usuário pressiona Ctrl-C para encerrar o script do Python.
Executar o bot Python
Para testar este aplicativo, primeiro é necessário definir a variável de ambiente OPENAI_KEY. Se você estiver usando Mac OS X ou Linux, faça da seguinte forma:
No prompt de comando do Windows, você pode fazer isso da seguinte maneira:
Você pode encontrar sua chave OpenAI na página Início rápido do desenvolvedor. Das duas chaves mostradas nesta página, use a chamada "Secret" (Segredo).
Depois de configurar a chave em seu ambiente, inicie o chat digitando python chat.py e comece a conversar com o bot! Veja abaixo um exemplo de interação com ele:
Trabalhar com outras linguagens além do Python
Você pode adaptar o exemplo do Python a outras linguagens, mas pode não ter uma biblioteca OpenAI disponível. Isso não é um problema, porque a API OpenAI é uma API HTTP razoavelmente padrão que você pode acessar por meio de solicitações HTTP brutas.
Para saber como enviar uma solicitação para uma determinada predefinição de Playground, você pode usar o mesmo botão "Export Code" (Exportar código), mas, desta vez, selecione a guia "curl" para ver a solicitação HTTP.
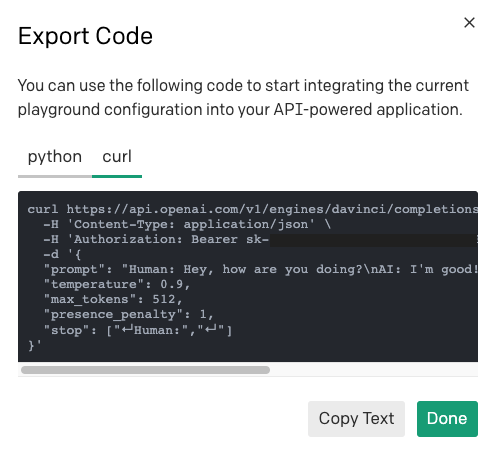
Você pode usar o comando curl para entender qual é a URL, os cabeçalhos e a carga útil e, em seguida, traduzi-los para o cliente HTTP escolhido em sua linguagem de programação.
Conclusão
Esta foi uma longa viagem! Espero que agora você tenha conseguido uma boa compreensão da API OpenAI e de como trabalhar com GPT-3.
Deseja aprender a usar GPT-3 com a Twilio e Python? Escrevi um tutorial de chatbot de SMS GPT-3, e o meu colega Sam Agnew também escreveu um divertido tutorial do GPT-3 com uma fanfic do Dragon Ball.


Recursos relacionados
Twilio Docs
De APIs a SDKs e aplicativos de amostra
Documentação de referência de API, SDKs, bibliotecas auxiliares, guias de início rápido e tutoriais para sua linguagem e plataforma.
Centro de Recursos
Os mais recentes e-books, relatórios do setor e webinars
Aprenda com especialistas em engajamento do cliente para melhorar sua própria comunicação.
Ahoy
Centro da comunidade de desenvolvedores da Twilio
Melhores práticas, exemplos de código e inspiração para criar comunicações e experiências de engajamento digital.