Automatisierte Skripterstellung für Headless Browser in Node.js mit Playwright
Time to read:
April 18, 2020
Autor:in:

Manchmal sind die Daten die wir benötigen online verfügbar, allerdings nicht über eine öffentliche API. Web Scraping kann in solchen Fällen hilfreich sein, allerdings nur, wenn die Daten über eine Webseite statisch verfügbar sind. Entwickler haben das Glück, dass alle Aufgaben, die sie manuell im Browser durchführen, mithilfe von Playwright automatisiert werden können. Playwright ist eine Node-Bibliothek, die vom gleichen Team entwickelt wurde wie Puppeteer und die eine High-Level-API zum Automatisieren von Aufgaben in verschiedenen Browsern bietet.
Ich zeige nun, wie wir mithilfe von Playwright programmgesteuert mit Webseiten interagieren können. Wir verwenden in diesem Beispiel das Tool Native Land Digital. Dabei handelt es sich um ein großartiges Projekt, mit dem Menschen mehr über ihre lokale indigene Geschichte erfahren können. Zwar gibt es in diesem Fall eine API, aber sie ruft die Standortdaten lediglich in Form von Geo-Koordinaten ab, nicht als benutzerfreundliche Adresse. Unser Ziel ist es, Code zu schreiben, mit dem wir programmgesteuert eine Adresse eingeben und herausfinden können, welches indigene Land dem betreffenden Standort entspricht.
Einrichten von Abhängigkeiten
Als Erstes müssen wir eine aktuelle Version von Node.js und npm installieren.
Wir navigieren zu dem Verzeichnis, in dem wir den Code speichern möchten, und führen den folgenden Befehl auf dem Terminal aus, um ein Paket für dieses Projekt zu erstellen:
Das Argument --yes durchläuft alle Eingabeaufforderungen, die wir ansonsten ausfüllen oder überspringen müssten. Wir haben jetzt eine package.json-Datei für unsere App und können den folgenden Befehl auf dem Terminal ausführen, um Playwright zu installieren:
Hinweis: Playwright umfasst Binärcodes für eine Reihe unterschiedlicher Browser, d. h., es kann bei der Installation zu einem starken Anstieg des Netzwerk-Datenverkehrs kommen.
Starten von Playwright und Erstellen eines Screenshots einer Seite
Als Erstes starten wir Playwright, navigieren zu einer Webseite und erstellen einen Screenshot der betreffenden Seite. Für die Beispiele in diesem Tutorial arbeiten wir mit Chromium.
Nachfolgend findest du „Hello World“-Code, um einen Screenshot der Seite zu machen. Wir legen eine Datei mit dem Namen index.js an und geben den folgenden Code darin ein:
Anschließend führst du den Code mit node index.js auf deinem Terminal aus, und zwar vom gleichen Verzeichnis, in dem der Code gespeichert ist. Nach ein paar Sekunden öffnest du das gespeicherte Bild example.png. Das Ganze sollte in etwa so aussehen:
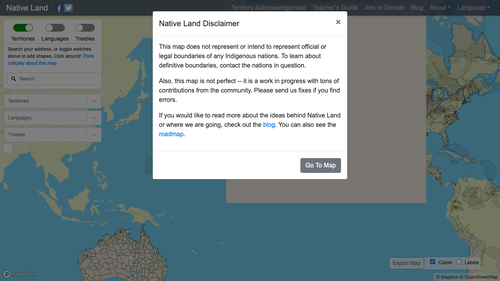
Je nachdem, wie schnell der Code ausgeführt wird, sieht der Screenshot eventuell ein wenig anders aus. Dies kann daran liegen, dass die Zeit für das Einblenden des modalen Haftungsausschluss-Fensters nicht ausreichte. Wenn ich meinen eigenen Code mehrmals ausführe, sieht der Screenshot jedes Mal ein bisschen anders aus. Keine Panik also, falls dein eigener Screenshot nicht dem hier abgebildeten entspricht.
Mit der Funktion page.waitFor() erreichst du, dass dein Skript eine bestimmte Anzahl von Millisekunden abwartet, bevor weitere Befehle ausgeführt werden. In einigen Fällen ist das ein Muss, damit deine Skripte sozusagen auf „menschlichere“ Weise mit den Seiten interagieren – vor allem, wenn es auf den Seiten Animationen gibt, deren Ausführung Zeit in Anspruch nimmt. Du solltest auch sicherstellen, dass du nicht versuchst, mit Dingen auf der Seite zu interagieren, die noch nicht existieren. Genau dafür ist die Funktion page.waitForSelector() gedacht, die einen speziellen CSS-Selektor nutzt und darauf wartet, dass ein zur betreffenden Beschreibung passendes Element erscheint. Davon machen wir später noch Gebrauch.
Bevor wir fortfahren, müssen wir das modale Fenster loswerden, denn nur dann können wir durch Interaktion mit der Seite weitere hilfreiche Informationen abrufen. Wir brauchen einen guten CSS-Selektor, um direkt im Code auf das modale Fenster zuzugreifen. Wenn du im Browser deiner Wahl mit der linken Maustaste auf ein Element klickst, siehst du eine Option des Typs „Element untersuchen“.
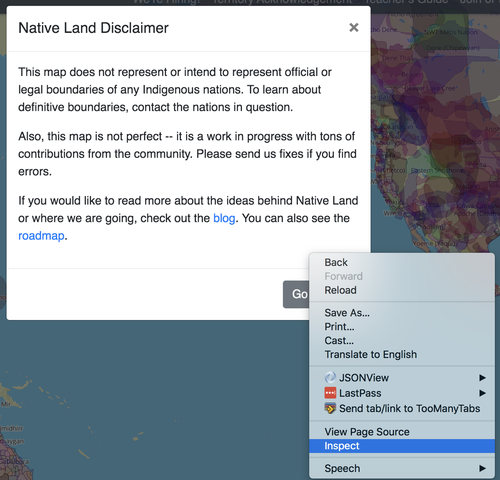
Wenn du sie auswählst, wird der HTML-Code des Elements als modal-footer-Klasse mit einem direkt untergeordneten button-Element dargestellt.

Interagieren mit den Elementen einer Webseite
In Playwright gibt es die Methoden page.click zum Anklicken eines DOM-Elements und page.type zum Eingeben von Text. Um auf die modale Schaltfläche zu klicken, verwenden wir den CSS-Selektor .modal-footer > button. Dieser wiederum nutzt den CSS-Selektor Kindkombinator, um die von uns gesuchte Schaltfläche zu finden.
Ändere deinen Code so, dass du auf die Schaltfläche klicken kannst, und mach dann einen anderen Screenshot:
Wenn du den neuen Code ausführst, sollte der neue Screenshot in etwa so aussehen:
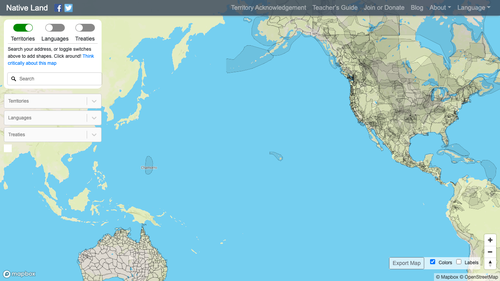
Das modale Fenster ist nicht mehr da, und der Rest der Seite wird geladen. Da wir eine Eingabe in das Textfeld vornehmen möchten, benötigen wir einen CSS-Selektor dafür.
Das Textfeld ist ein input-Feld mit einem placeholder-Element, d. h., wir können den Attributselektor nutzen, um 'input[placeholder=Search]' zu erhalten. Außerdem können wir die weiter oben erwähnte Funktion page.waitForSelector() verwenden, um darauf zu warten, dass die Dropdown-Liste mit den Ortsvorschlägen angezeigt wird, nachdem wir den Namen des gesuchten Orts eingegeben haben.

Wir schreiben nun neuen Code für die Eingabe in dieses Textfeld und verwenden den Selektor li.active > a, um auf Ortsvorschläge zu warten, bevor wir einen weiteren Screenshot erstellen:
Wir warten außerdem 300 Millisekunden, bevor wir Text in das Suchfeld eingeben. So geben wir der Seite ein bisschen mehr Zeit zum Laden. Falls das bei dir nicht funktioniert, spiel einfach ein wenig mit den Zahlen herum. Der aktuellste Screenshot sollte so aussehen:
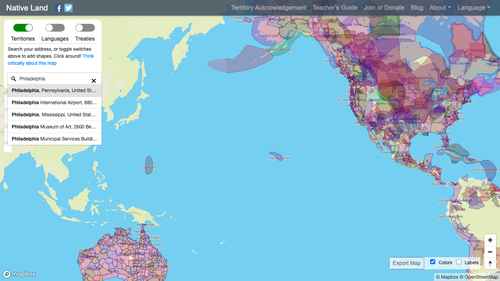
Die Ortsvorschläge werden nun angezeigt, und wir müssen nur auf den ersten Vorschlag klicken, um ein Ergebnis zu erhalten.
Lesen von Daten auf der Seite
Mit Playwright kannst du außerdem die HTML-Elemente bewerten, um die darin enthaltenen Eigenschaften innerText und innerHTML zu lesen. Genau so greifen wir auf die Daten zu.
Nachdem wir den Ort eingegeben haben und die Ergebnisse geladen wurden, untersuchen wir das Element, in dem der Text erscheint, damit wir einen passenden CSS-Selektor dafür erstellen können.
Das ist im Prinzip ganz einfach. Es handelt sich um einen div mit der results-tab-Klasse. .results-tab sollte also funktionieren. Dieses Element existiert allerdings direkt nach dem Laden der Seite. Wenn wir also Code schreiben möchten, der auf die eigentlichen Ergebnisse wartet, müssen wir .results-tab > p verwenden, um auf die untergeordneten Knoten zu verweisen, die sich auf dieser Registerkarte befinden.
Mit der Funktion page.$, die einen CSS-Selektor erfordert, erstellen wir ein Objekt für das gewünschte Element. Danach wenden wir die evaluate-Methode auf das ElementHandle-Objekt an, um Code zu schreiben, der direkt auf den Inhalt des Elements zugreift.
Modifiziere jetzt ein letztes Mal deinen Code in index.js an:
Wenn du diesen Code erneut ausführst, sollte der Ortstext auf deiner Konsole erscheinen und dein letzter Screenshot sollte wie folgt aussehen:
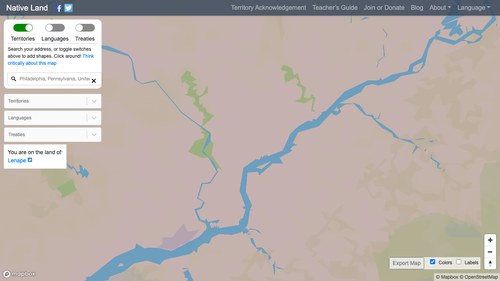
Wir sehen in diesem Fall, dass sich die Stadt Philadelphia auf dem Land der Lenape befindet.
Der Weg zum richtigen Ergebnis und die weiteren Schritte
Es kann recht knifflig sein, die korrekte Funktionsweise dieser Skripte hinzubekommen. Ein nützlicher Debugging-Trick besteht darin, Playwright im Non-Headless-Modus auszuführen, um sich einen genaueren Einblick zu verschaffen. Am besten machst du dies beim ersten Start des Browsers, indem du { headless: false } als optionalen Parameter angibst. Bei Verwendung dieser Option kann Playwright sogar zum Testen von Chrome-Erweiterungen eingesetzt werden.
Verglichen mit anderen Bibliotheken besteht einer der größten Vorteile von Playwright darin, dass es mit verschiedenen Browsern genutzt werden kann, nicht nur mit Chromium. Wenn du durch die Codebeispiele in diesem Blog-Beitrag gehst und const browser = await playwright.chromium.launch(); in const browser = await playwright.firefox.launch(); änderst, um FireFox statt Chromium zu verwenden, siehst du, wie sich dies auf das Verhalten deines Codes auswirkt.
Du bist jetzt in der Lage, Webseiten programmgesteuert zu bearbeiten, und kennst eine Methode, um die darin enthaltenen Daten auf eine Art und Weise aufzurufen, die mit statischen Web Scraping-Tools nicht möglich ist. Ich bin gespannt auf die Ergebnisse deiner Entwicklungsarbeit! Ihr könnt mich gerne kontaktieren, um eure Erfahrungen zu teilen oder Fragen zu stellen.
- E-Mail: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (Live-Code-Streaming): Sagnewshreds


Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.