4 Web Scraping Tools in Node.js
Time to read:
April 29, 2020
Autor:in:
Prüfer:in:

Manchmal sind die Daten die wir benötigen online verfügbar, allerdings nicht über eine REST API. Als JavaScript-Entwickler hast du allerdings Glück, denn in Node.js stehen dir zahlreiche Tools zum Scrapen und Parsen von Daten aus Webseiten zur Verfügung.
Lerne vier dieser Bibliotheken kennen und erfahre, wie sie funktionieren und wie sie sich voneinander unterscheiden.
Dazu müssen die aktuellen Versionen von Node.js (mindestens 12.0.0) und npm auf deinem Rechner installiert sein. Führe den Terminalbefehl in dem für den Code bestimmten Verzeichnis aus:
Für einige dieser Anwendungen verwenden wir die Got-Bibliothek, um HTTP-Anfragen zu stellen. Installiere diese deshalb mit diesem Code im selben Verzeichnis:
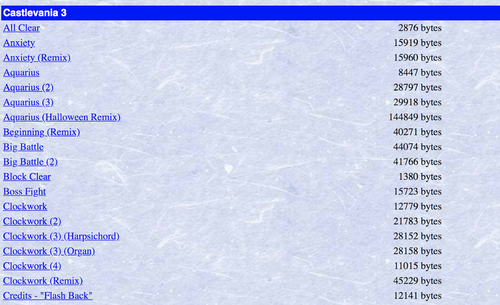
Als Beispiel werden wir versuchen, die Links zu verschiedenen MIDI-Dateien auf dieser Webseite des Video Game Music Archive mit zahlreichen Nintendo Musikdateien zu finden.
Tipps und Tricks für Web Scraping
Bevor wir uns speziellen Tools widmen, gibt es einige allgemeine Themen, die nützlich sind, egal, für welche Methode du dich letztendlich entscheidest.
Bevor wir Code zum Parsen des gewünschten Content schreiben, müssen wir uns den HTML-Content ansehen, der vom Browser gerendert wird. Jede Webseite ist anders – um die richtigen Daten zurückzuerhalten, ist daher ein gewisses Maß an Kreativität, Mustererkennung und Experimentierfreudigkeit gefragt.
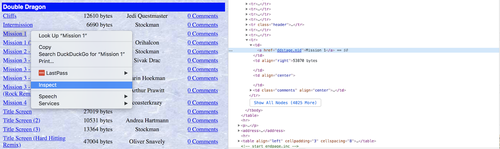
Es gibt hilfreiche Entwickler-Tools, die dir in den meisten aktuellen Browsern zur Verfügung stehen. Wenn wir mit der rechten Maustaste auf das gewünschte Element klicken, können wir den HTML-Code prüfen, der dem Element zugrunde liegt. So verschaffen wir uns einen genaueren Einblick.
Außerdem müssen wir häufiger spezifischen Content filtern. Dazu bieten sich CSS-Selektoren an, denen du immer wieder in den Codebeispielen dieses Tutorials begegnest. Nutze diese, um HTML-Elemente zusammenzutragen, die ein spezielles Kriterium erfüllen. Für viele Web-Scraping-Situationen sind auch reguläre Ausdrücke sehr hilfreich. Benötigst du etwas mehr Granularität, kannst du darüber hinaus Funktionen schreiben, um die Elementinhalte zu filtern, wie zum Beispiel zur Feststellung, ob sich ein Hyperlink-Tag auf eine MIDI-Datei bezieht:
Nicht vergessen: viele Websites verhindern Web Scraping in ihren Servicevereinbarungen. Das musst du also vorab klären. Jetzt wird es allerdings Zeit, dass wir uns das mal genauer anschauen.
jsdom
jsdom ist eine reine JavaScript-Implementierung von zahlreichen Webstandards für Node.js, ein großartiges Tool zum Testen und Scraping von Webanwendungen. Installiere es mit dem folgenden Befehl in deinen Terminal:
Du benötigst nur den folgenden Code, um alle Links zu MIDI-Dateien auf der zuvor erwähnten Video Game Music Archiv-Seite zusammenzutragen:
Dabei ist a ein ganz einfacher Abfrageselektor für den Zugriff auf alle Hyperlinks der Seite. Zusätzlich profitieren wir von ein paar Funktionen zum Filtern dieses Inhalts, damit uns wirklich nur die MIDI-Dateien angezeigt werden. Die noParens()-Filterfunktion nutzt einen regulären Ausdruck für den Ausschluss aller MIDI-Dateien, die Klammern enthalten. Dabei handelt es sich lediglich um alternative Versionen der Lieder.
Speichere diesen Code in einer Datei mit dem Namen index.js und führe ihn zusammen mit dem Befehl node index.js in deinem Terminal aus.
Möchtest du mehr darüber wissen, lies mein anderes Tutorial, dass ich zu jsdom geschrieben habe.
Cheerio
Cheerio ist eine Bibliothek, die jsdom ähnelt, aber diese Entwicklung ist etwas leichtgängiger und schneller. Es implementiert einen Teil des Kerns von jQuery, daher werden die Funktionen dieses Tools vielen JavaScript-Entwicklern bekannt vorkommen.
Nutze diesen Befehl für die Installation:
Der Code zum Erfüllen desselben Tasks ist sehr ähnlich:
Wie wir sehen, ist die Verwendung von Funktionen zum Filtern des Inhalts in die API von Cheerio integriert. Ein zusätzlicher Code zur Konvertierung der Elemente in einen Array ist also nicht nötig. Ersetze den Code in index.js mit dem neuen Code und führe ihn erneut aus. Das sollte aufgrund der Leichtgängigkeit von Cheerio jetzt alles merkbar schneller gehen.
Möchtest du mehr darüber erfahren, empfehle ich dir dieses andere Tutorial, das ich zur Verwendung von Cheerio geschrieben habe.
Puppeteer
Puppeteer unterscheidet sich sehr von den beiden zuvor genannten, denn es handelt sich dabei primär um eine Bibliothek für Headless-Browser-Scripting. Puppeteer bietet eine High-Level-API zur Steuerung von Chrome oder Chromium über das DevTools-Protokoll. Es überzeugt durch seine Vielseitigkeit, denn du kannst damit Code schreiben, um mit Webanwendungen zu interagieren oder diese zu bearbeiten, statt lediglich statische Daten zu lesen.
Nutze diesen Befehl für die Installation:
Web Scraping mit Puppeteer sieht ganz anders aus im Vergleich zu den beiden zuvor genannten Tools. Anstelle von Code, den du schreibst, um reine HTML-Elemente aus einer URL abzufassen und diese einem Objekt hinzuzufügen, schreibst du Code, der im Kontext eines Browsers ausgeführt, der HTML einer bestimmten URL verarbeitet. Daraus entsteht dann ein reales Dokument-Objekt-Modell.
Das folgende Code-Snippet weist den Puppeteer-Browser an, zu unserer gewünschten URL zu navigieren und auf alle Elemente mit demselben Hyperlink zuzugreifen, die wir zuvor geparst haben:
Beachte, dass wir immer noch einige Logiken schreiben, um die Links auf der Seite zu filtern. Der Unterschied besteht allerdings darin, dass wir nicht mehr Filterfunktionen deklarieren, sondern „inline“ vorgehen. Wir nutzen zwar auch Code aus gängigen Textbausteinen, um dem Browser zu sagen, was zu tun ist. Aber wir benötigen kein weiteres Node-Modul für eine Anfrage an die Website, die wir für das Web Scraping verwenden. Im Allgemeinen halten diese einfachen Dinge zwar eher auf, aber Puppeteer ist dennoch sehr nützlich, wenn du es mit Seiten zu tun hast, die nicht statisch sind.
Wenn du daran interessiert bist, die Funktionen von Puppeteer zur Interaktion mit dynamischen Webanwendungen detaillierter kennenzulernen, lege ich dir ein weiteres von mir verfasstes Tutorial ans Herz, in dem wir uns intensiver mit Puppeteer beschäftigen.
Playwright
Playwright ist eine weitere Bibliothek für Headless-Browser-Scripting aus der Feder desselben Teams, das auch Puppeteer entwickelte. Seine API und Funktionsweise ähnelt Puppeteer sehr stark, aber es arbeitet browserübergreifend und funktioniert mit FireFox, Webkit und auch Chrome/Chromium.
Nutze diesen Befehl für die Installation:
Der Playwright-Code für diesen Task sieht im Großen und Ganzen genauso aus, wir müssen nur explizit angeben, welchen Browser wir nutzen:
Dieser Code führt alles genauso aus wie der Code im Abschnitt zu Puppeteer und verhält sich ähnlich. Playwright ist allerdings vielseitiger, da du es für mehrere Browsertypen nutzen kannst. Führe diesen Code auch einmal bei anderen Browsern aus und sieh dir an, wie sich das auf dein Skript auswirkt.
Ich habe, wie zu den anderen Bibliotheken auch, ein Tutorial verfasst, in dem ich näher auf Playwright eingehe, falls du mehr dazu wissen möchtest.
Die endlose Weite des World Wide Web
Wir wissen nun, wie man programmgesteuert Inhalte aus Webseiten extrahieren kann, das heißt, wir haben jetzt Zugang zu einer gigantischen Datenquelle mit allem, was wir für unsere Projekte brauchen. Zu beachten ist, dass jegliche Änderungen am HTML einer Webseite zu Fehlern in unserem Code führen können. Daher ist es wichtig, dass wir alles auf dem neuesten Stand halten, wenn wir Anwendungen auf der Basis von Web Scraping entwerfen.
Ich bin gespannt auf eure Ergebnisse. Ihr könnt mich gerne kontaktieren, um eure Erfahrungen zu teilen oder Fragen zu stellen.
- E-Mail: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (Live-Code-Streaming): Sagnewshreds



Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.