Build a Question-Answering over Docs SMS Bot with LangChain in Python
Time to read:
June 15, 2023
Written by
Reviewed by

With Natural Language Processing (NLP), you can chat with your own documents, such as a text file, a PDF, or a website. Read on to learn how to build a generative question-answering SMS chatbot that reads a document containing Lou Gehrig's Farewell Speech using LangChain, Hugging Face, and Twilio in Python.
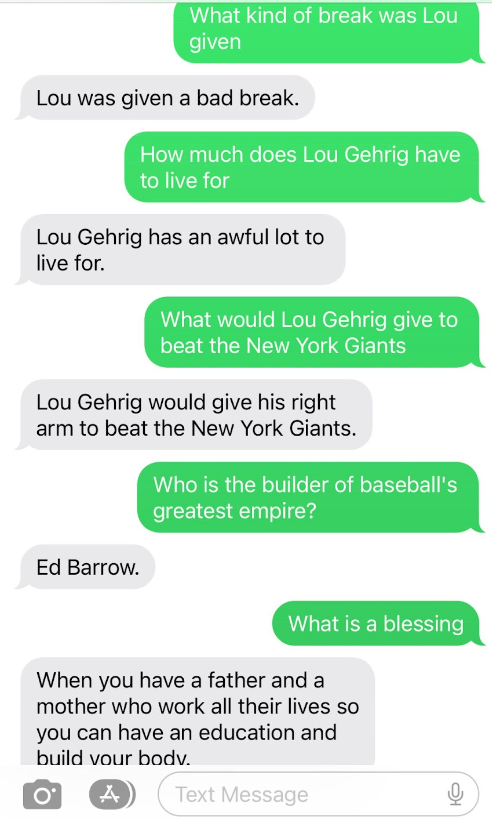
LangChain Q&A
LangChain is an open-source tool that wraps around many large language models (LLMs) and tools. It is the easiest way (if not one of the easiest ways) to interact with LLMs and build applications around LLMs.
LangChain makes it easy to perform question-answering of those documents. Picture feeding a PDF or maybe multiple PDF files to a machine and then asking it questions about those files. This could be useful, for example, if you have to prepare for a test and wish to ask the machine about things you didn’t understand.
Prerequisites
- A Twilio account - sign up for a free Twilio account here
- A Twilio phone number with SMS capabilities - learn how to buy a Twilio Phone Number here
- Hugging Face Account – make a Hugging Face Account here
- Python installed - download Python here
- ngrok, a handy utility to connect the development version of our Python application running on your machine to a public URL that Twilio can access.
Configuration
Since you will be installing some Python packages for this project, you will need to make a new project directory and a virtual environment.
If you're using a Unix or macOS system, open a terminal and enter the following commands:
If you're following this tutorial on Windows, enter the following commands in a command prompt window:
Set up Hugging Face Hub
The Hugging Face Hub offers over 120k models, 20k datasets, and 50k demos people can easily collaborate in their ML workflows. As mentioned earlier, this project needs a Hugging Face Hub Access Token to use the LangChain endpoints to a Hugging Face Hub LLM. After making a Hugging Face account, you can get a Hugging Face Access Token here by clicking on New token. Give the token a name and select the Read Role.
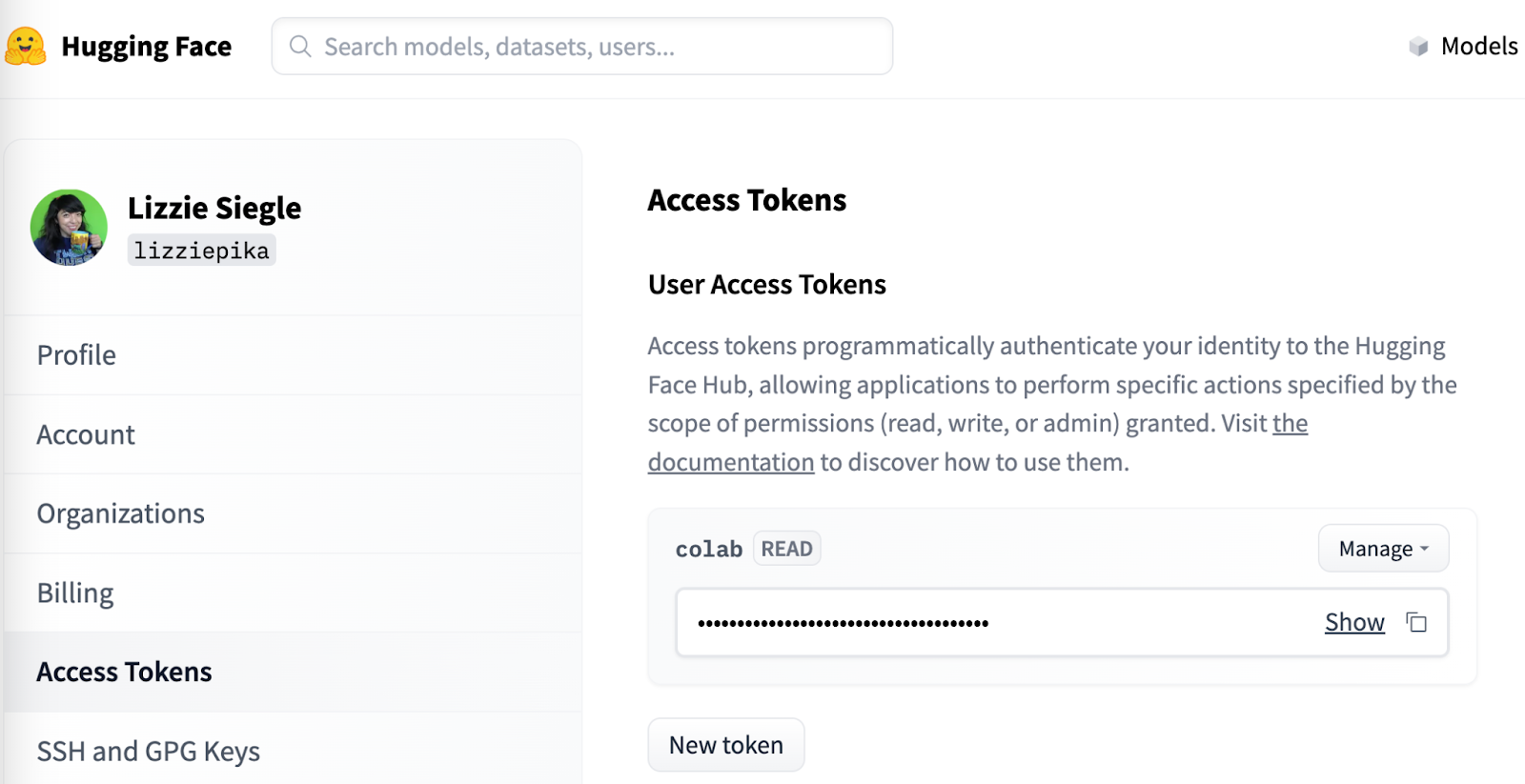
Alternatively, you could use models from, say, OpenAI.
On the command line in your root directory, run the following command on a Mac to set the token as an environment variable.
For the Windows command, check out this blog post on environment variables.
Now let's build that LangChain question-answering chatbot application.
Answer Questions from a Doc with LangChain via SMS
Inside your lc-qa-sms directory, make a new file called app.py.
At the top of the file, add the following lines to import the required libraries.
Beneath those import statements, make a helper function to write to a local file from a URL, and then load that file from the local file storage with LangChain's TextLoader library. Later the file will be passed over to the split method to create chunks.
In this tutorial, the file will be Lou Gehrig's famous speech, which is why the output_file is named "lougehrig.txt".

You could alternatively use a local file.
Next, add the following code for a helper function to split the document into chunks. This is important because LLMs can't process inputs that are too long. LangChain's CharacterTextSplitter function helps us do this–setting chunk_size to 1000 and chunk_overlap to 10 keeps the integrity of the file by avoiding splitting words in half.
Now convert the chunked document into embeddings (numerical representations of words) with Hugging Face and store them in a FAISS Vector Store. Faiss is a library for efficient similarity search and clustering of dense vectors.
That makeEmbeddings function will make it more efficient to retrieve and manipulate the stored embeddings to conduct a similarity search to get the most semantically-similar documents to a given input which the LLM needs to best answer questions in the following helper function.
The final helper function defines and loads the Hugging Face Hub LLM to be used with your Access Token and starts the request on a similarity search embedded with some input question to the selected LLM, enabling a question-and-answer conversation.
declare-lab/flan-alpaca-large is a LLM. You could use others from Hugging Face Hub such as google-flan-t5-xl. They are trained on different corpuses and this tutorial uses flan-alpaca-large because it's faster.
Lastly, make a Flask app using the Twilio REST API to call the helper functions and respond to inbound text messages with information pulled from the text file.
Your complete app.py file should look like this:
On the command line, run python app.py to start the Flask app.
Configure a Twilio Number for the SMS Chatbot
Now, your Flask app will need to be visible from the web so Twilio can send requests to it. ngrok lets you do this. With ngrok installed, run ngrok http 5000 in a new terminal tab in the directory your code is in.
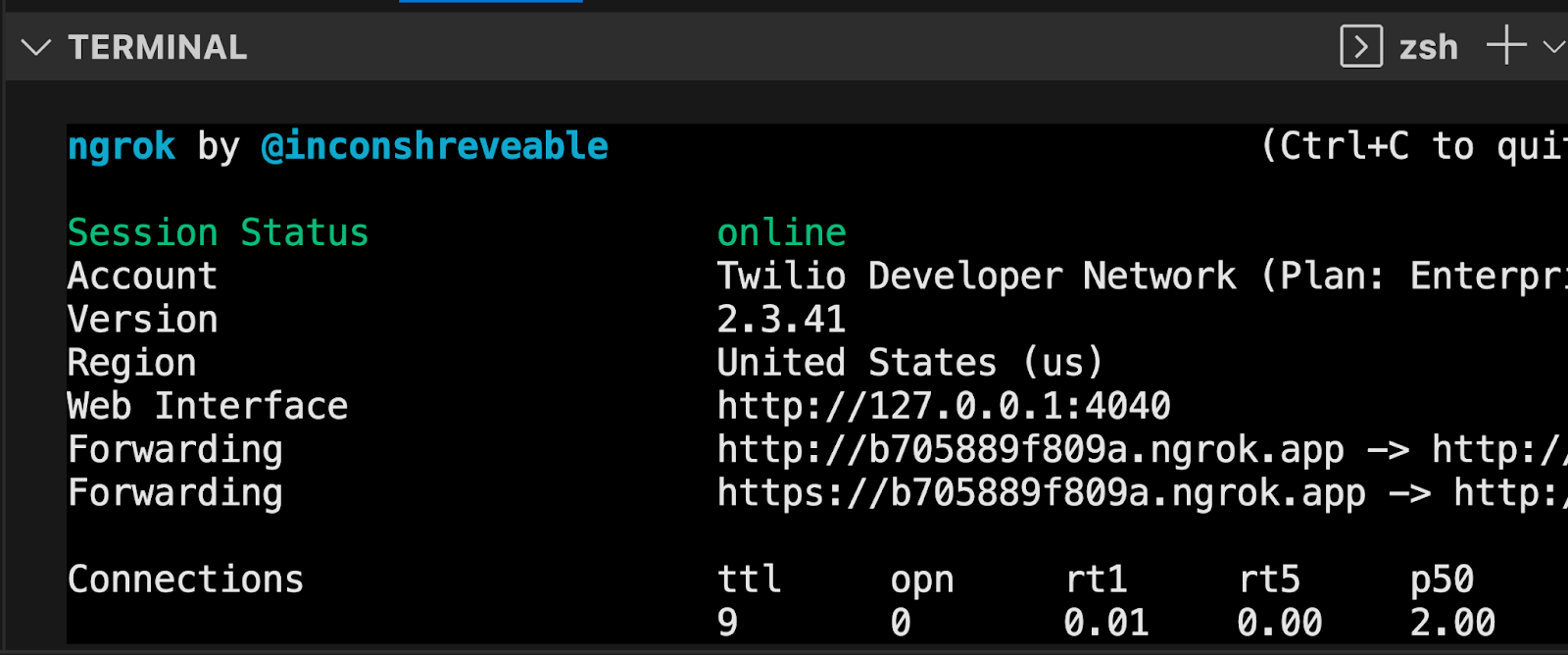
You should see the screen above. Grab that ngrok Forwarding URL to configure your Twilio number: select your Twilio number under Active Numbers in your Twilio console, scroll to the Messaging section, and then modify the phone number’s routing by pasting the ngrok URL with the /sms path in the textbox corresponding to when A Message Comes In as shown below:
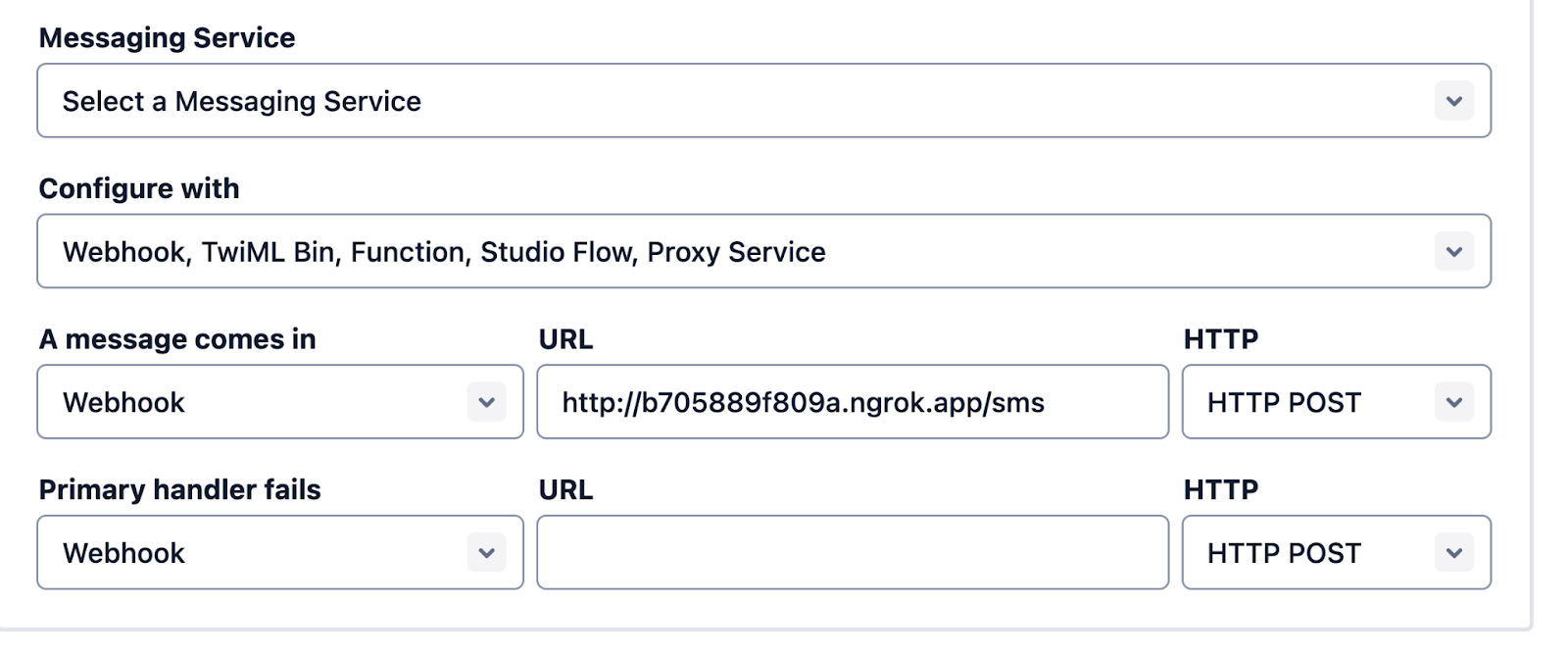
Click Save and now your Twilio phone number is configured so that it maps to your web application server running locally on your computer and your application can run. Text your Twilio number a question relating to the text file and get an answer from that file over SMS!
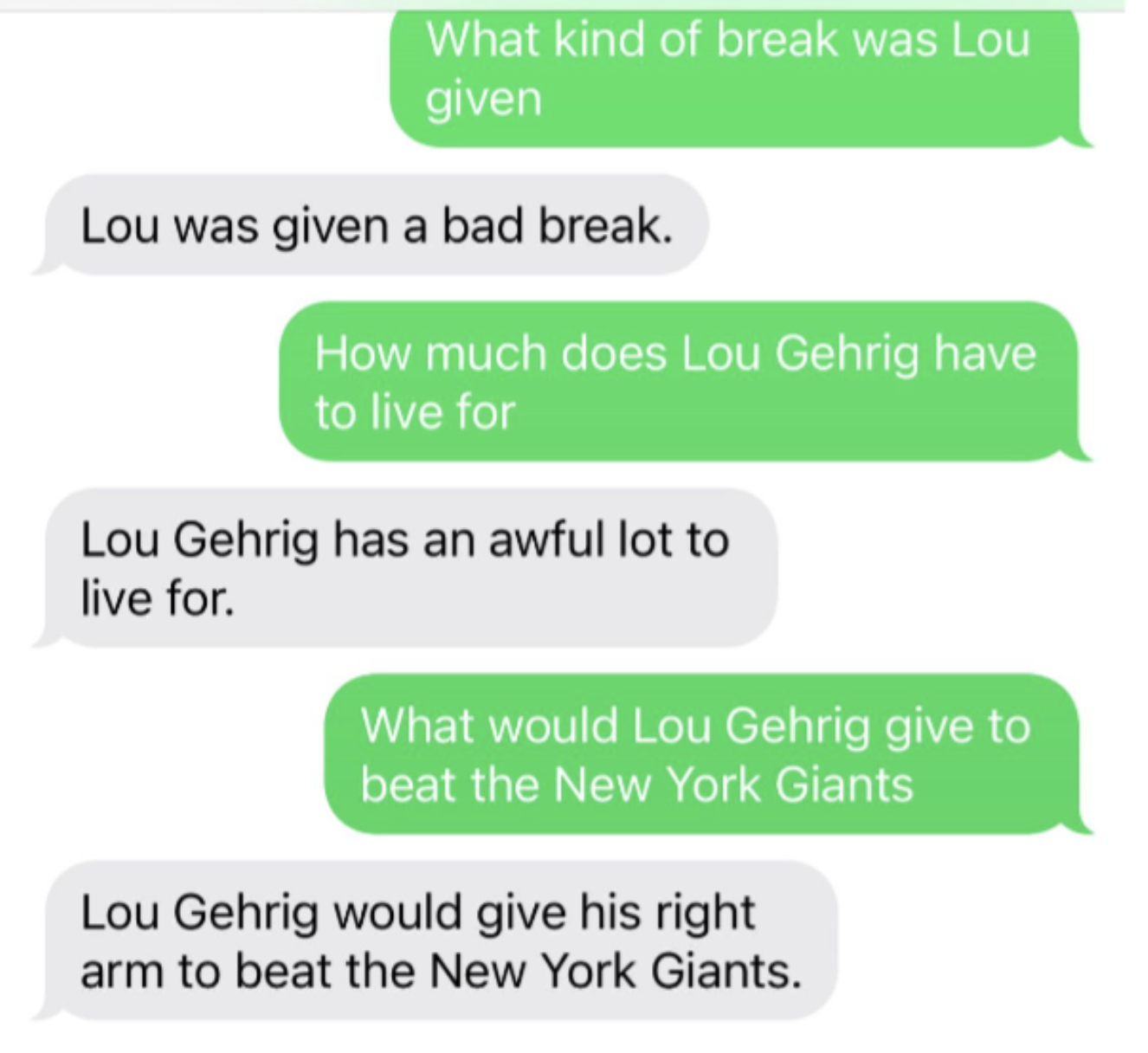
There's so much you can do with document-based question-answering. You can use a different LLM, use a longer document than a text file containing Lou Gehrig's famous speech, use other types of documents like a PDF or website (here's LangChain's docs on documents), store the embeddings elsewhere, and more. Other than a SMS chatbot, you could create an AI tutor, search engine, automated customer service agent, and more.
Let me know online what you're building!
- Twitter: @lizziepika
- GitHub: elizabethsiegle
- Email: lsiegle@twilio.com



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.