Web Speech APIを用いたブラウザでのテキスト読み上げ
Time to read:
August 22, 2019
執筆者

Web Speech APIには、音声合成(テキスト読み上げ)と、音声認識(音声からテキストへの変換)という2つの機能があります。SpeechSynthesis APIを使用すると、ブラウザ上で音声を選択して任意のテキストを読み上げることができます。
アプリケーション内での音声アラートや、WebサイトでのAutopilot駆動のチャットボット利用など、Web Speech APIはWebインターフェースを強化する大きな可能性を秘めています。ここでは、Webアプリケーションでの音声読み上げの実行方法について説明します。
必要なもの
SpeechSynthesis APIについて学び、このアプリケーションを構築するには、次の準備が必要です。
- 最新のブラウザ(このAPIは、主なデスクトップブラウザとモバイルブラウザでサポートされています)
- テキストエディター
準備ができたら作業用のディレクトリを作成し、そのディレクトリにこのHTMLファイルとこのCSSファイルをダウンロードします。これらのファイルが同じフォルダにあり、CSSファイルの名前がstyle.cssであることを確認します。ブラウザでHTMLファイルを開くと、次の内容が表示されます。
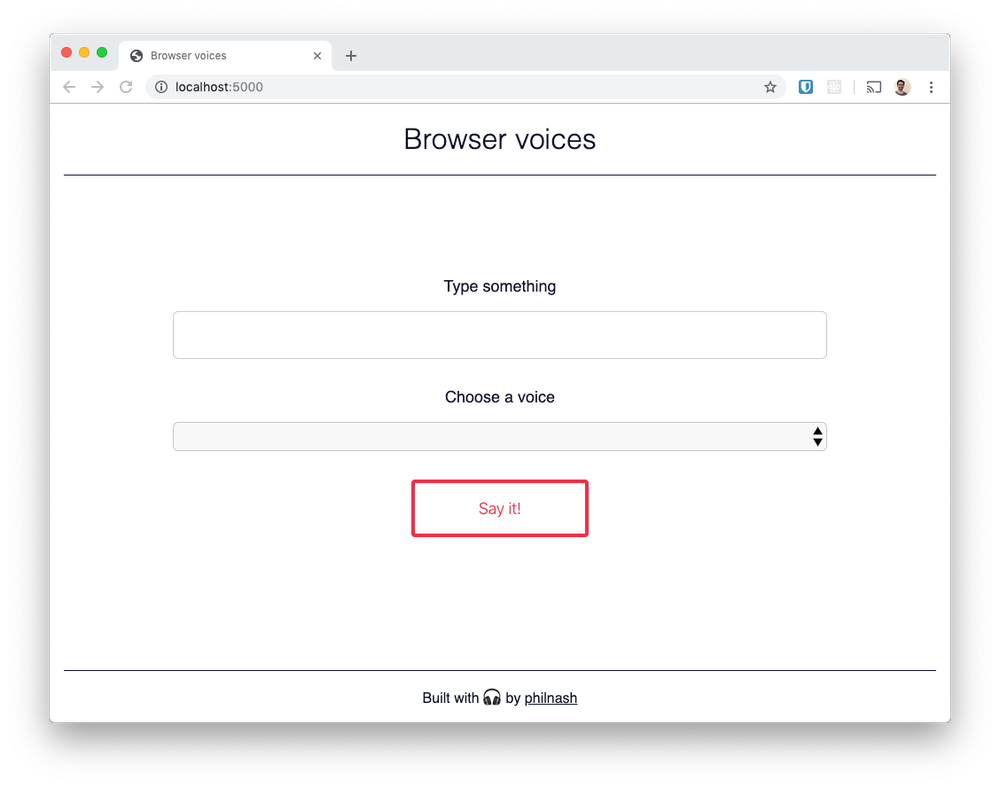
では、このAPIを使用して、ブラウザでの読み上げを行いましょう。
Speech Synthesis API
この小さなアプリケーションでの作業を始める前に、ブラウザの開発ツールを使用して読み上げを実行してみます。任意のWebページにて開発ツールのコンソールを開き、次のコードを入力します。
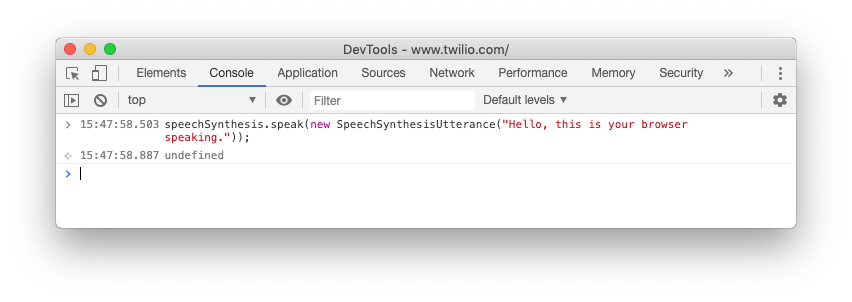
ブラウザはデフォルト音声で「Hello, this is your browser speaking.」と読み上げます。これを少し変更してみます。
上の例では、読み上げ対象のテキストを含むSpeechSynthesisUtteranceを作成し、その音声コマンドをspeechSynthesisオブジェクトのspeakメソッドに渡しました。これで読み上げ用の音声コマンドのキューに入れられ、ブラウザでの読み上げが開始されます。複数の音声コマンドをspeakメソッドに送ると、順番に読み上げられます。
それでは、ダウンロードしておいたスターターコードを使用してこれを小さなアプリに変換し、読み上げ用のテキストを入力してブラウザでの音声を選択してみましょう。
Webアプリケーションにおける音声合成
ダウンロードしておいたHTMLファイルをテキストエディターで開きます。まずはフォームを接続して、入力したテキストが送信後に読み上げられるようにします。音声を選択する機能は、その後に追加します。
HTML下部の<script>タグで、DOMContentLoadedイベントをリスニングし、必要な要素のいくつかのリファレンスを選択します。
次にフォーム上のsubmitイベントをリスニングし、イベント発生時に入力されたテキストを取得します。そのテキストからSpeechSynthesisUtteranceを作成し、speechSynthesis.speakに渡します。最後に入力ボックスを空にし次の読み上げ用テキストが入力されるのを待ちます。
ブラウザでHTMLを開き、入力に任意のテキストを入力します。この時点では<select>ボックスは無視できます。このボックスは次のセクションで使用します。「Say it」と入力し、その語句がブラウザで読み上げられるのを聞きます。
ブラウザでの読み上げ実行コードはこのようにシンプルですが、音声を選択したい場合はどうすればよいでしょうか。ページ上に使用可能な音声一覧のドロップダウンを設置し、選択できるようにしましょう。
テキスト読み上げ用音声の選択
ページ上の<select>要素のリファレンスを取得することと、使用可能な音声と現在使用中の音声を格納するためにこれから使用する、いくつかの変数の初期化を行う必要があります。これをスクリプトの上部に追加します。
次に、使用可能な音声情報を持つselect要素を取り込む必要があります。これを行うための新しい関数を作成します。複数回呼び出す可能性があるからです(詳細は後述)。speechSynthesis.getVoices()を呼び出すと、使用可能なSpeechSynthesisVoiceオブジェクトが返されます。
音声オプションの追加に加えて、現在選択されている音声を検出する必要もあります。音声を選択済みの場合は、currentVoiceオブジェクトで確認できます。未選択の場合は、voice.defaultプロパティでデフォルト音声を検出できます。
populateVoiceは、即時呼び出しができます。音声ページを読み込んだ直後に、その音声リストを返すブラウザもありますが、そうでないブラウザの場合は、音声リストを非同期に読み込む必要があります。読み込みが完了すると「voiceschanged」イベントが発行されます。ただし、このイベントを発行しないブラウザもあります。
想定しうるすべてのシナリオに対応するため、populateVoicesを即座に呼び出し、これを「voiceschanged」イベントへのコールバックとして設定します。
ページを再読み込みしてください。<select>要素に、使用可能なすべての音声(音声がサポートする言語を含む)が取り込まれています。音声の選択方法と使用方法については、この後で説明します。
select要素の「change」イベントをリスニングし、イベント発生時に<select>要素のselectedIndexを使用してcurrentVoiceを選択します。
次に、特定の音声コマンドで特定の音声を使用するために、作成する音声コマンドに音声を設定する必要があります。
ページを再読み込みし、別の音声や読み上げ内容を選択してチェックしてください。
追加情報: 視覚的な読み上げインジケータの構築
様々な音声を使用できる音声合成機能を構築しましたが、もう1つ、おもしろい機能を追加してみましょう。読み上げ音声コマンドが発行するイベントには、アプリケーションからの音声応答を可能にするものも多数あります。この小さなアプリの仕上げとして、ブラウザが音声を読み上げている間、アニメーションが表示されるようにしてみましょう。すでにアニメーション用のCSSは追加してあります。これを有効にするには、ブラウザが読み上げる間の「speaking」クラスを<main>要素に追加する必要があります。
スクリプト上部で<main>要素のリファレンスを取得します。
これで、音声コマンドのstartイベントとendイベントをリスニングして、「speaking」クラスの追加や削除を実行できます。しかし、アニメーションの途中でクラスを削除すると、アニメーションがスムーズにフェードアウトしません。このため、「animationiteration」イベントを使用してアニメーションの繰り返しの終了をリスニングしてから、クラスを削除する必要があります。
これで、読み上げの開始と同時に背景が青く点滅し、音声コマンドが終了すると点滅が止まるようになりました。
ブラウザの可能性を広げる音声読み上げ
この記事では、Web Speech APIからSpeech Synthesis APIを起動して操作する方法を説明しました。このアプリケーションのコードはすべてGitHubにあり、動作確認や編集はGlitchで行えます。
今回このAPIを使用してみて、ブラウザボットとして独自のアプリケーションを構築できる手ごたえを得たことにワクワクしています。これからもこのブログで詳しく紹介していきますので、どうぞお楽しみに。
Speech Synthesis APIはもうお使いですか?それとも使用を検討中ですか?下のコメント欄で、ぜひご意見をお聞かせください。メール(philnash@twilio.com)やTwitter(@philnash)でもお待ちしています。

