ガイド: Node.jsでログを記録する方法
Time to read:
May 06, 2019
執筆者
レビュー担当者

JavaScriptで開発を始める際に最初に学ぶことの1つは、console.logを使用してイベントなどをコンソールにロギングする方法でしょう。JavaScriptのデバッグ方法を検索すると、console.logのシンプルな利用方法に関するブログや、StackOverflowの記事が数百件ヒットします。console.logは一般的な手法ですが、不要なログステートメントを本番コードに残さないためにno-consoleなどのlinterルールも登場しています。しかし、特定の情報を意図的にロギングする場合は、どうすれば良いのでしょうか?
この記事では、情報をロギングするさまざまなケースを紹介します。さらに、Node.jsにおけるconsole.logとconsole.errorの違いや、ユーザーコンソールを混乱させずにロギングをライブラリに組み込む方法についても解説します。
第1の理論: Node.js
console.logまたはconsole.errorはブラウザやNode.jsで使用できますが、Node.jsで使用する際に注意すべき重要な点があります。例えば、Node.js環境でindex.jsというファイルに、次のコードを記述します。
node index.jsコマンドでこのコードをターミナルで実行すると、2つの出力が表示されます。
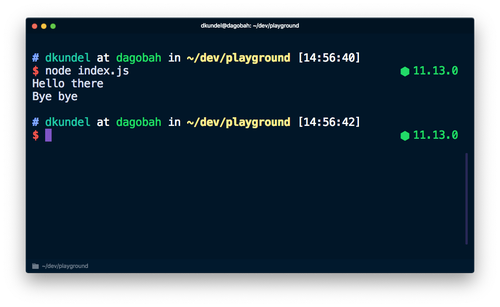
この2つは同じように見えますが、システムにおける取り扱いは異なります。Node.jsドキュメントのconsoleセクションによると、console.logはstdoutに対して出力しているのに対し、console.errorはstderrを使用しています。
あらゆるプロセスには、stdin、stdout、stderrという3つの標準ストリームがあります。stdinストリームは、プロセスへの入力を処理します。例えば、ボタンを押す動作、リダイレクトされた出力などです(のちほど解説します)。stdoutストリームは、アプリケーションの出力です。最後のstderrは、エラーメッセージストリームです。stderrを使用する理由とタイミングについては、こちらの記事をご覧ください。
エラーメッセージストリームは簡単に言うと、リダイクト(>)やパイプ(|)演算子を使用して、アプリケーションの結果から、エラーや診断の情報を分離できるようにするものです。>はコマンドの出力をファイルにリダイレクトし、一方、2>はstderrの出力をファイルにリダイレクトします。例えば下記のコマンドは、「Hello there」をhello.logというファイルにパイプし、「Bye bye」をerror.logというファイルにパイプします。
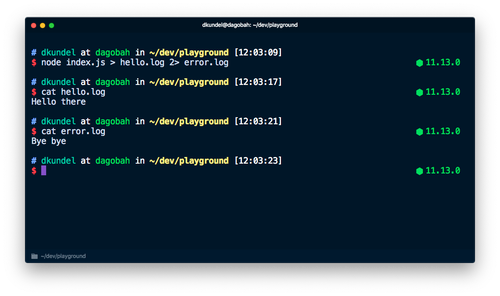
ロギングのタイミング
ロギングに関する基本的な技術情報を少し学んできましたが、もう少し別のロギングが必要となるユースケースを見てみましょう。ユースケースは主に以下の5つに分類できます:
- 開発中に発生する予期しない動作に対するクイックデバッグ
- 分析または診断のためのブラウザベースのロギング
- 受信したリクエストのログや発生する可能性のある障害を記録するサーバーアプリケーション向けのログ
- ユーザーの問題解決を支援するライブラリ向けのオプションデバッグログ
- 進捗状況、確認メッセージ、エラーを出力するためのCLIの出力
この記事では、最初の2つについては紹介を省略し、残り3つのNode.jsベースのユースケースに焦点を当てます。
サーバーアプリケーションログ
サーバーで発生するイベントをログとして記録する理由はさまざまです。例えば、受信したリクエストをロギングすると、何人のユーザーに404エラーが発生しているか、どのようなエラーか、どのUser-Agentが使用されたのかなどの統計情報などを抽出できます。さらに、問題が発生したタイミングや理由も把握できます。
もし今回の記事を試したいという場合は、新しいプロジェクトディレクトリを作成してください。その後、プロジェクトディレクトリにこちらにコードを記述、実行するためのindex.jsファイルを作成し、expressをインストールします。
次にサーバーとミドルウェアを設定し、あらゆるリクエストに対してconsole.logを出力するため、下記のコードをindex.jsファイルに記述します。
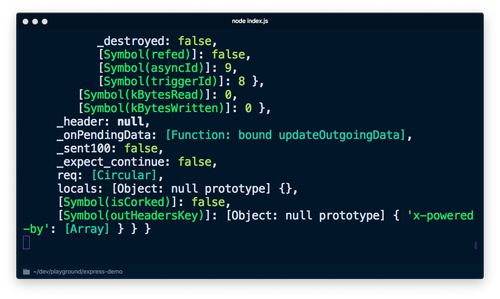
ここでは、console.log('%O', req)を使用しオブジェクト全体をロギングします。console.logは、内部でutil.formatを使用し、%Oやほかのプレースホルダをサポートします。詳しくは、Node.jsドキュメントを参照してください。
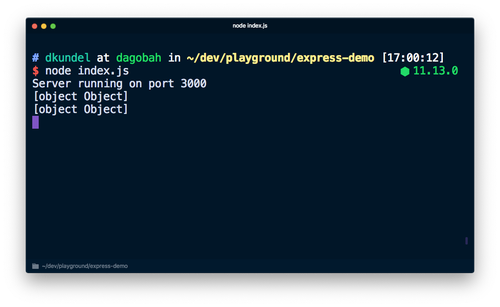
node index.jsを実行し、http://localhost:3000を開くと、大量の情報が出力されます。
先ほどのコードをconsole.log('%s', req)に変更すると、今回は必要が無いオブジェクト内部の情報が出力されなくなります。
必要な情報のみを出力する独自のログ関数を記述することもできますが、まずは基本に戻り、我々がどんな情報を必要としているかを見ていきましょう。メッセージそのものに注目しがちですが、以下のような追加情報も必要になります。
- タイムスタンプ - イベントがいつ発生したか把握するため
- コンピューター/サーバー名 - 分散システムを実行している場合
- プロセスID - 複数のノードプロセスをpm2などを使用して実行している場合
- メッセージ - 実際のメッセージと一部コンテンツ
- スタックトレース - エラーをロギングする場合
- その他の変数/情報など
加えて、全ての情報はstdoutとstderrに出力されますが、異なるログレベルを設定し、そのレベルごとにログを構成しつつ、フィルタリングできる機能があると便利でしょう。
そのためには、processのさまざまな部分にアクセスしてあらゆる情報を取得し、膨大な量のJavaScriptを記述する方法もあります。しかし、Node.js最大の長所であるnpmエコシステムではいろいろなライブラリがすでに用意されているため、すぐ利用できます。
個人的には、高速で優れたエコシステムを発揮するpinoが好みです。pinoがロギングにどのように役立つか見ていきましょう。ありがたいことに、リクエストをロギングするためのexpress-pino-loggerパッケージがすでに用意されています。
まず、pinoとexpress-pino-loggerを両方ともインストールします。
その後、ロガーとミドルウェアを使用するようにindex.jsファイルを更新します。
このスニペットでは、pinoのloggerインスタンスを作成してexpress-pino-loggerに渡した後、app.useを呼び出し、新しいロガーミドルウェアを作成します。さらに、サーバーを開始する際に呼び出していたconsole.logをlogger.infoに置き換え、logger.debugをルートパスに追加し、それぞれ異なるログレベルを表示させています。
node index.jsを再び実行してサーバーを再起動すると、各行で先ほどとはまったく異なる内容のJSONが出力されます。http://localhost:3000を開くと、新たなJSONデータが次の行に表示されます。
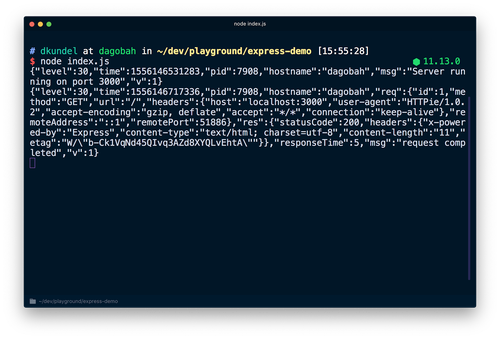
このJSONにはタイムスタンプなど先ほど説明したすべての情報が記載されています。また、logger.debugステートメントもターミナルに出力されなくなります。出力させるにはloggerの標準ログレベルを変更する必要があります。先ほどのコードでは、loggerインスタンスの作成時に、ログレベルをprocess.env.LOG_LEVELの値に設定しています。この値を変更するか、デフォルトのinfoをそのまま使用できます。LOG_LEVEL=debug node index.jsを実行すると、ログレベルを変更できます。
さて、ログレベルを変更する前に、現時点の出力では人間が判別できないという問題を解決しましょう。pinoはパフォーマンスを重視し、意図的にこのような出力になっているため、|を使用して出力をパイプし、あらゆるログ処理を別のプロセスに移動する必要があります。このログ処理には、人間が判別可能な形式への変換や、クラウドホストへのアップロードなどの処理も含まれます。こうした処理をtransportsと呼びます。transportsに関するドキュメントを参照し、pinoのエラーがstderrに書き込まれない理由についても確認してください。
pino-prettyツールを使用し、より判別しやすいバージョンのログを見てみましょう。以下をターミナルで実行します。
すべてのログが|演算子によりpino-prettyコマンドにパイプされます。この処理では出力を整形し、重要な情報については色分けするようしています。再度、http://localhost:3000に対してリクエストを送信すると、debugメッセージも表示されます。
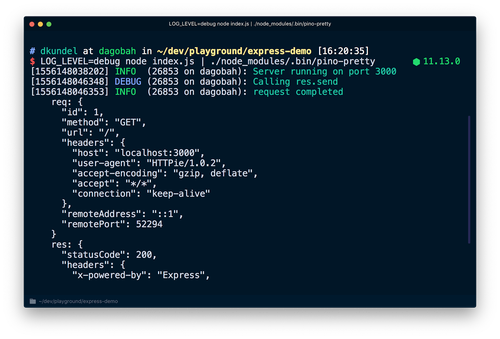
また、すでに存在するさまざまなtransportsを用いてログを修飾または変換できます。例えば、pino-coladaを使用しログに絵文字を表示できます。これらはローカル開発に役立ちます。また、サーバーを本番環境で実行した後、ログを別のtransportにパイプすることもできます。>を使用してディスクに書き込み、後で処理するか、teeなどのコマンドを使用して書き込みと同時に処理を実行できます。
pinoのドキュメントには、ログファイルのローテーション、フィルタリング、別のファイルへのログの書き込みなどの情報も記載されています。
ライブラリのログ
ここまでは、サーバーアプリケーションのログを効率的に書き込む方法を見てきましたが、自分が作成するライブラリにも同じ技術を適用できないでしょうか?
この場合、デバッグ目的でライブラリのログを記録する場合でも、ユーザーのアプリケーションを混乱させないようにする必要があります。デバッグが必要になった場合、ユーザー自身がログを有効化できるように構成しなければなりません。ライブラリは標準では何もせず、ユーザーの判断に委ねるべきです。
このよい例がexpressです。expressの内部ではさまざまなことが行われているため、アプリケーションをデバッグするときに内部を覗いてみるとよいでしょう。expressドキュメントでは、DEBUG=express:*をコマンドに追加できると説明しています。
既存のアプリケーションでコマンドを実行すると、問題のデバッグに役立つ多くの出力が追加で得られます。
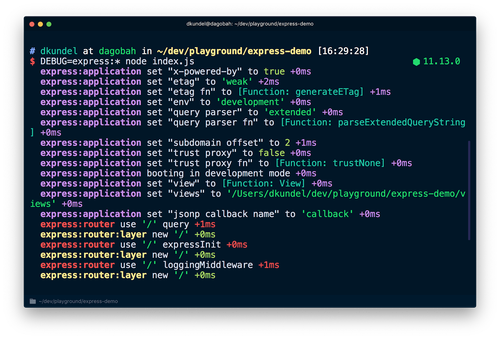
デバッグロギングを有効にしていない場合は、こうした出力は表示されません。この際に利用するのが、その名もdebugパッケージです。
このパッケージは指定した「名前空間」の内部でメッセージを書き込むことができます。ライブラリを使用するユーザーが名前空間かワイルドカードをDEBUG環境変数に含めていれば、それらが出力されます。
ライブラリをシミュレートするrandom-id.jsという名前のファイルを作成し、以下のコードを記述します。
このライブラリでは新しいdebugロガーをmylib:randomidという名前空間で作成し、さらに、2つのログメッセージを記録します。先ほど使ったindex.jsで使用しましょう。
DEBUG=mylib:randomid node index.jsコマンドでサーバーを再起動すると、「ライブラリ」のデバッグログが出力されます。
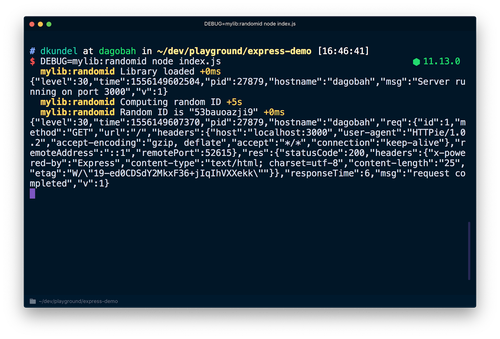
さらにライブラリを使用するユーザーがこのデバッグ情報をpinoログに記録する場合、pino-debugというpinoチームが提供するライブラリを使用し、ログを正しくフォーマットできます。
次のコードでライブラリをインストールします。
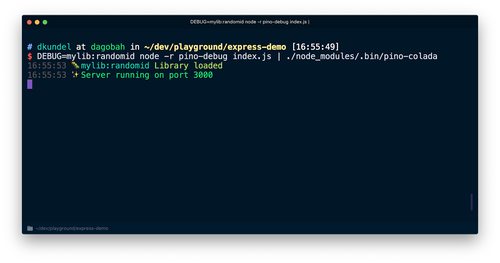
pino-debugは、debugを初めて使用する前に初期化する必要があります。最も簡単な初期化方法は、Node.jsの-rまたは--requireフラグを使用し、スクリプト開始前にモジュールを要求することです。pino-coladaがインストール済みの状態で、以下のコマンドとともにサーバーを再び実行します。
これでライブラリのデバッグログが、アプリケーションログと同じフォーマットで表示されます。
CLIの出力
この記事で紹介する最後のケースは、ライブラリではなく、CLIの特殊なロギングケースです。ここでは、ロジックログとCLI出力の「ログ」を区別して考えます。ロジックログの場合は、debugなどのライブラリを使用します。この方式を用いるとCLIの具体的なユースケースに制限されることなく、自分やほかの人がロジックを再利用できます。
Node.jsでCLIを構築する場合は、視覚的に目立つ色、スピナー、フォーマットなどを追加し、見栄えよく仕上げることができます。ただし、CLIを構築する際に考慮すべきシナリオがいくつかあります。
1つ目のシナリオは、CLIを継続的インテグレーション(CI)システムで使用する場合です。この場合は、出力の色や見栄えのよい装飾を省略する必要があります。一部のCIシステムは、CIという環境フラグを設定しています。CIの基準を確実に遵守するには、多くのCIシステムをサポートしているis-ciなどのパッケージを使用します。
chalkなどの一部のライブラリは、CIをあらかじめ検出し、出力するテキストの色を自動的に省略します。どのような手順になるか見てみましょう。
npm install chalkコマンドでchalkをインストールし、cli.jsというファイルを作成します。
その後、以下のコードをファイルに記述します。
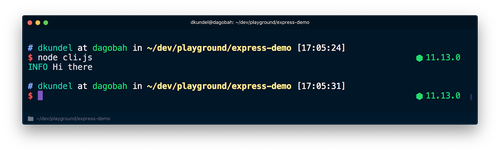
node cli.jsコマンドでスクリプトを実行すると、色付きで出力されます。
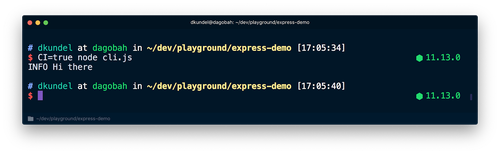
CI=true node cli.jsコマンドを実行すると、色が省略されます。
他にもstdoutがターミナルモードで実行されているかどうかを判断するシナリオがあります。ターミナルモードの場合は、コンテンツがターミナルに書き込まれるため、boxenなどを使用し、見栄えのよい出力を表示できます。それ以外の場合は、出力がファイルまたはパイプ先にリダイレクトされます。
stdin、stdout、stderrがターミナルモードかどうか検証するには、それぞれのストリームのisTTY属性を確認します。例えば、process.stdout.isTTYを用います。TTYは「teletypewriter」の略であり、この場合はターミナルを指しています。
この値は、Node.jsプロセスの開始方法に応じて各ストリームで異なります。詳細については、Node.jsドキュメントの「プロセスI/O」セクションを参照してください。
ここからは、さまざまな状況でprocess.stdout.isTTYの値がどのように変化するか見ていきましょう。cli.jsファイルを次のように更新し、変化を確認します。
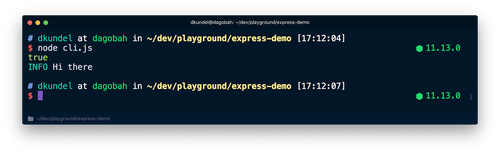
ターミナルでnode cli.jsコマンドを実行すると、trueと出力され、続けて色付きのメッセージが表示されます。
その後、同じスクリプトを実行し、出力をファイルにリダイレクトします。
実行後に内容を確認すると、今度はundefinedに続いて色なしのプレーンなメッセージが出力されます。これは、stdoutがリダイレクトされたため、ターミナルモードがオフとなったことが理由です。chalkはそれぞれのストリームでisTTYについて検証するsupports-colorを使用しています。
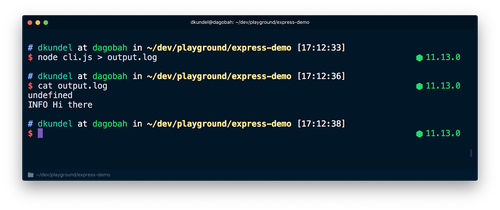
先ほど確認したようにchalkなどのツールではこのように動作しますが、CLI開発においては、CLIがCIモードで実行される状況や、出力がリダイレクトされる状況があるということを、常に把握しておくようにします。CLIから出力されるデータをターミナルで見栄えよく表示し、isTTYがundefinedの場合は解析しやすい形に切り替えることができれば、CLIを利用するユーザーの体験を向上させることができます。
まとめ
JavaScriptを使いconsole.logでロギングを開始することは簡単です。しかし、コードを本番環境に移行する場合は、注意すべきことが多くあります。この記事では、さまざまなロギング方法と利用可能なソリューションのさわりの部分を紹介しました。もちろん、すべての情報を網羅しているわけではありません。興味のあるオープンソースプログラムをいくつか参照し、そのプログラムがどのようにロギングの問題を解決しているか、またどのツールを使用しているか確認することをお勧めします。あらゆる情報をログとして記録できますが、そのログをすべて出力しても意味がありません😉

このブログで取り上げてほしいツールや質問がある場合は、お気軽にご連絡ください。
I can't wait to see what you build!
- Twitter: @dkundel
- Email: dkundel@twilio.com
- GitHub: dkundel
- dkundel.com


