Web Speech APIを利用しブラウザで音声を認識する方法
読む所要時間: 10 分
February 10, 2020
執筆者
レビュー担当者

Web Speech APIには、音声合成(text to speech)と、音声認識(speech to text)という2つの機能があります。以前の記事では音声合成について解説しましたが、今回はSpeechRecognition APIを利用したブラウザの音声認識、音声書き起こし方法について解説します。
ユーザーが発する音声コマンドを認識できれば、通常よりも没入感のあるインターフェースを提供でき、音声操作を好むユーザーを獲得しやすくなります。2018年のGoogleの報告によると、全世界のオンライン人口のうち27%がモバイルデバイスで音声検索を使用しています。今回解説するブラウザの音声認識機能を用いて、あなたのWebアプリケーションで基本的な音声検索からインタラクティブbotまで、多岐にわたる機能を提供できます。
次のセクションからAPIのしくみを理解し、何ができるか実際に確認してみましょう。
必要なもの
APIを実際に体験できるサンプルアプリケーションを作成するために次のツールを用意します。
- Google Chrome
- テキストエディタ
今回はHTML、CSS、JavaScriptを使用してアプリケーションを作成します。作業用の新しいディレクトリを作成し、このディレクトリにstarter HTMLとCSSを保存します。保存したHTMLファイルをブラウザで開くと以下のスクリーンショットと同じ画面が表示されます。
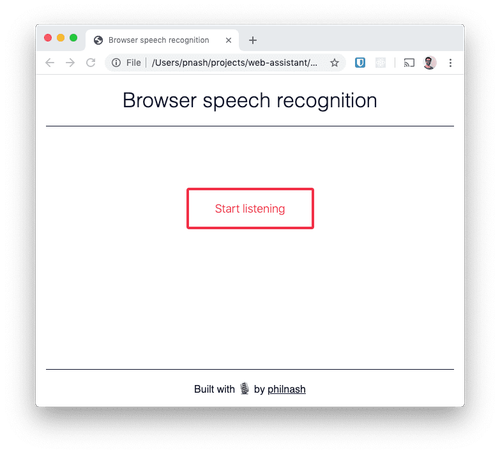
次のセクションからブラウザで音声を聞き取り、認識する方法を見ていきましょう。
SpeechRecognition API
音声認識機能をサンプルアプリケーションに追加する前に、ブラウザが提供する開発者ツールで使用感を確認しておきましょう。Chromeデベロッパーツールを開き、コンソールに以下のコードを入力します。
このコードを実行すると、Chromeがマイクの使用許可を求めます。ページをWebサーバーにホストしている場合は、使用許可をブラウザで記憶しておきます。マイクの使用を許可し、何か話しかけてください。会話を終了するとSpeechRecognitionEventがコンソールに記録されます。
たった3行のコードですが、多くの処理が実行されます。まず、SpeechRecognition APIのインスタンス(先頭にベンダー名の「webkit」を追加)を作成し、このインスタンスに音声認識サービスから受け取る結果をすべて記録ように指示します。最後に、聞き取りと認識を開始するように指示しています。
さらに、このインスタンスには標準の設定も反映されています。たとえば、オブジェクトが結果を受け取ると、聞き取りを停止します。文字起こしを続けるには、startメソッドを再び呼び出す必要があります。また、音声認識サービスから受け取るのは最後の結果のみです。こちらについては、連続した音声認識を有効にし、話している途中で認識結果を出力することもできます。設定方法については後ほど解説します。
コンソールに出力されているSpeechRecognitionEventの中身を確認しましょう。最も重要なプロパティはresultsです。これはSpeechRecognitionResultが格納されているリストです。このスクリーンショットでは聞き取りを停止する前に一言しか話していないため、1つのresultオブジェクトのみが表示されています。このオブジェクトにはさらにSpeechRecognitionAlternativeを格納したリストが含まれています。SpeechRecgnitionAlternativeに含まれているリストの先頭に、音声認識の文字起こし結果と信頼度(0~1)が表示されます。デフォルトで結果は1つしか表示されませんが、音声認識サービスからさらに多くの結果を受け取るように設定できます。話した言葉に一番近い結果をユーザーに選択してもらう場合に便利な機能です。
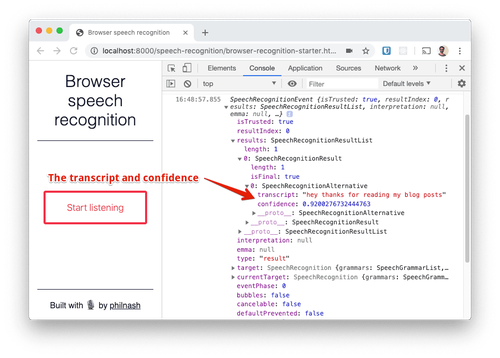
動作のしくみ
この機能をブラウザでの音声認識と呼ぶことは正確ではありません。Chromeは現在、音声を取得してGoogleのサーバーに送信し、文字に変換します。このため、現時点ではChromeと一部のChromiumベースのブラウザでのみ音声認識をサポートしています。
Mozillaは音声認識のサポートをFirefoxに組み込みました。この機能はGoogle Cloud Speech APIの使用交渉を進めているためFirefox Nightly版でフラグを有効化した場合にのみ使用できます。Mozillaは独自のDeepSpeechエンジンを開発中ですが、ブラウザでサポートを重視し、このような形でGoogleのサービスも使用することにしました。
SpeechRecognitionはサーバーサイドAPIを使用するため、ユーザーはオンライン環境でAPIを使用する必要があります。オフラインでのローカル音声認識も間もなくリリースされる予定ですが、現在は制限されています。
先ほどダウンロードしたスターターコードと開発ツールのコードを使用して小規模なアプリケーションを作成し、ユーザーの音声をライブ認識してみましょう。
Webアプリケーションでの音声認識
先ほどダウンロードしたHTMLを開き、一番下の<script>タグの間に処理を実装します。まずDOMContentLoadedイベントをリスニングし、使用するHTML要素へのリファレンスを取得します。
ブラウザがSpeechRecognitionまたはwebkitSpeechRecognitionオブジェクトをサポートしているかどうかを確認し、サポートしていない場合は続行できない旨のメッセージを表示します。
SpeechRecognitionにアクセスできる場合は、使用するための準備をします。音声を認識しているかどうかを示す変数を定義し、音声認識オブジェクトのインスタンスを作成します。さらに、開始、停止、および新しい結果への応答を行う3つの関数を定義します。
start関数では、音声認識を開始し、ボタンのテキストを変更します。さらに、メイン要素にクラスを追加し、ページでリスニング中を示すアニメーションを開始します。stop関数では、逆の操作を行います。
そして、音声認識の結果を受け取るとすべての結果をページにレンダリングします。このサンプルでは、直接DOM操作を実施し、先ほど説明したSpeechRecognitionResultオブジェクトを結果を表示する<div>に段落として追加します。最終結果と中間結果の違いを示すために、finalとマークされた結果にCSSクラスを追加します。
音声認識を開始する前に、このアプリケーションで使用する設定を適用しておきます。今回のバージョンでは、音声の終わりを検知した際に終了せず、結果を常時記録します。つまり、停止ボタンが押されるまでは、文字起こしの結果がページに常に表示されます。さらに、話している間も中間結果を表示するように設定します(Twilioにおいて音声通話中に<Gather>とpartialResultCallbackを使用し、常に音声認識できる動作とよく似ています)。そして、結果リスナーも追加しておきます。
最後に、ボタンにリスナーを追加し、音声認識を開始および停止できるようにします。
ブラウザを再度読み込み、動作を試してください。
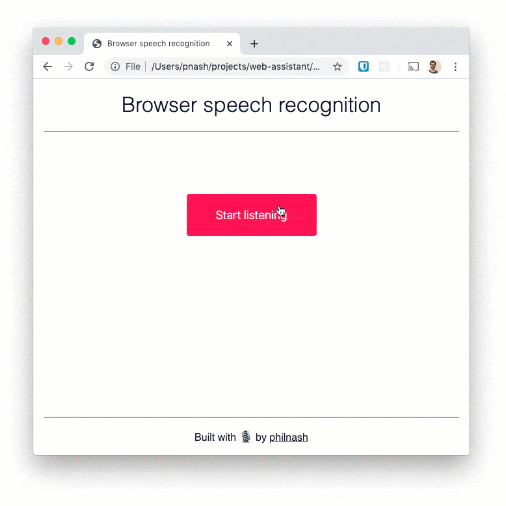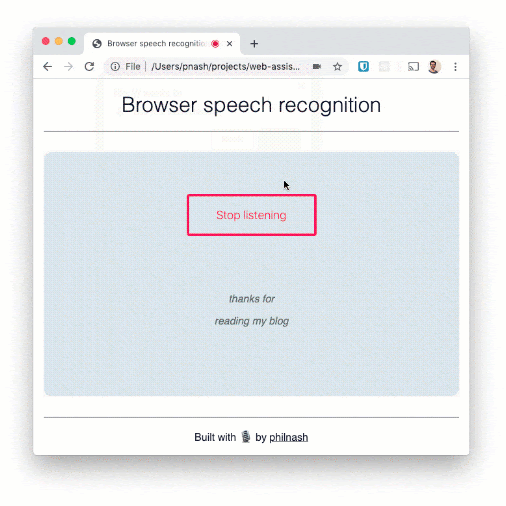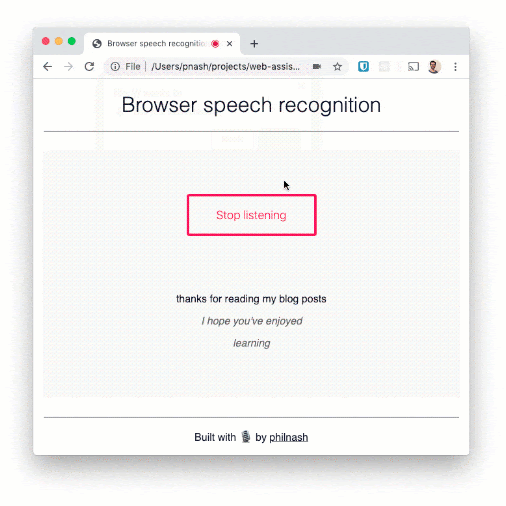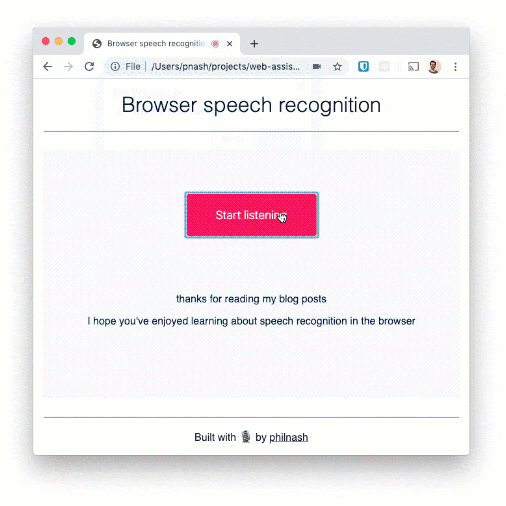
いくつかの文を読み上げ、ページに表示されることを確認します。この音声認識は単語の認識能力は高いものの、句読点はあまり得意ではありません。たとえば、ディクテーション(書き取り)に使用する場合は、もう少し開発を進める必要があります。
ブラウザに話しかけましょう
この記事では、ブラウザによる音声認識を解説しました。また、前回の記事では、ブラウザの読み上げ機能の設定方法を紹介しています。これらの手順とTwilio Autopilotを利用したアシスタントを併用すると、おもしろいプロジェクトを構築できるでしょう。
この記事のサンプルを実際に試したい場合は、Glitchで確認できます。ソースコードが必要な場合は、GitHubのweb-assistantリポジトリで取得できます。
音声を使用したユーザーインターフェースには、あらゆる可能性があります。たとえば、最近、音声ベースのブラウザゲームを見つけました。ぜひ、みなさんのプロジェクトを私のTwitter(@philnash)までお知らせください。


