Error Handling in Go: 6 Effective Approaches
Time to read:
July 22, 2024
Written by
Reviewed by
Error Handling in Go: 6 Effective Approaches
In languages like Java and C# error handling is primarily managed through the try-catch mechanism. When an error occurs within a try block, the catch block intercepts it, allowing the program to handle the error gracefully. This approach provides a structured way to deal with exceptions, ensuring that applications can respond to errors without crashing.
However, Go takes a fundamentally different approach to error handling. Instead of using exceptions, Go treats errors as values that can be returned from functions. This means that instead of catching exceptions, Go programs check for errors after calling a function and then decide how to handle them. This approach emphasizes explicit error handling over implicit exception handling, leading to clearer code and better error management practices.
In this article, we’ll take a look at some error handling techniques to help simplify how you manage errors in your code.
Prerequisites
Before going any further, ensure you have the following:
- Go installed on your system. You can download it from the official website
- A text editor or IDE of your choice to write and edit your Go code
- A project directory for the tutorial's code
The built-in error type
Go's built-in error type is foundational to its error-handling mechanism. This type is defined as an interface with a single method: Error(), which returns a string describing the error. Any type that implements this method satisfies the error interface, allowing you to create custom error types easily.
This simplicity and flexibility make the error type both powerful and easy to use, as it fits seamlessly into Go's overall design philosophy of straightforward, readable code.
Here’s how to implement the error type:
The built-in errors package provides a straightforward way to create error instances using the errors.New() function. This function takes a string and returns an error with that message. This simplicity encourages you to create meaningful error messages that can be easily understood and acted upon.
Using the error type often involves checking for errors immediately after a function call. This approach ensures that errors are handled at the point of occurrence, preventing them from propagating and causing more significant issues later in the execution flow.
Below is an example illustrating how to implement error handling for a division operation, specifically addressing the scenario of division by zero.
In the tutorial's project directory, create a new file named main.go. In that file, paste the code below.
In the code above, the divide() function returns an error if the denominator is zero, preventing a runtime crash, allowing the caller to handle the error appropriately. This pattern of returning errors explicitly and handling them immediately is a hallmark of Go's approach to error handling, promoting clear, maintainable, and robust code.
To run the code, the following command in your terminal:
You should see that it displays the result "Error: division by zero".

Return error values
Returning error values is the most common error handling pattern in Go, emphasizing explicit error checking and handling. In this pattern, functions return error values alongside their regular outputs, obligating the caller to verify these error values and act accordingly.
Let’s look at another example that will showcase returning error values. Replace the code in the main.go with the following code:
In the provided code, the readFile() function returns an error if the filename is empty. The caller promptly checks the error post-function call, ensuring proper error handling. This pattern aids in preventing unaddressed errors from escalating into broader issues throughout the execution flow.
Run the code using the go run command in your terminal.
You should see it display an error saying "filename cannot be empty":

Adopting this pattern fosters more defensive coding practices, enabling proactive anticipation and management of potential errors as they emerge.
Error wrapping
Error wrapping is a technique that provides additional context to errors, making them easier to debug and understand. Introduced in Go 1.13 , the fmt.Errorf() function facilitates error wrapping. This feature allows you to add context to errors while preserving the original error for later inspection.
Let’s look at another example that will showcase error wrapping. Replace the code in the main.go with the following code:
In this example, the openFile() function employs fmt.Errorf() with the %w verb to wrap the original error with contextual information. This wrapped error provides more information about the error's origin, making it easier to diagnose and fix. The original error remains intact, supporting the use of errors.Is() and errors.As() for error inspection and unwrapping.
Run the code using the go run command in your terminal.
You should see it display an error saying Error: openFile: filename cannot be empty:

Error wrapping contributes significantly to developing a more informative error reporting system. When you incorporate a detailed context within errors, the system becomes more self-explanatory, offering valuable insights into the circumstances surrounding the error's occurrence and potential causes for failure.
Custom error types
Creating custom error types enables you to tailor errors with extra context and functionality. When you implement the error interface, you can construct sophisticated error types that offer detailed insights into the error. This approach is particularly useful for defining domain-specific errors that require additional information beyond a simple error message.
Let’s look at yet another example that will demonstrate the usage of custom error types. Replace the code in the main.go with the following code:
In this example, the NotFoundError type generates a specific error message indicating that a resource was not found.
By defining a custom error type, you can incorporate additional properties and behaviors to the error, facilitating its management and troubleshooting. This method is particularly advantageous in complex applications where various error types demand unique handling approaches.
Utilizing custom error types improves code clarity and sustainability by rendering error handling more transparent and descriptive.
Run the code using the go run command in your terminal.
You should see it display an error saying "Error: Resource not found":

When you create and utilize custom error types, you can guarantee that errors are not merely managed but also conveyed distinctly to users. This strategy contributes to the development of more resilient and user-centric applications, as errors are more enlightening and comprehensible.
Logging errors
Logging errors is an essential practice for debugging and monitoring applications. The log package in Go offers a simple yet effective means to log errors and other messages.
Logging errors enables you to monitor issues as they arise, comprehend the application's state, and spot patterns that might signal deeper problems. This practice is vital for sustaining an application's health and performance, particularly in production environments.
Let’s look at another example that will demonstrate how to log errors. Replace the code in the main.go with the following code:
In this example, the performTask() function returns an error, which is subsequently logged using log.Printf(). This simple logging statement provides immediate visibility into the error, making it easier to diagnose and fix.
Run the code using the go run command in your terminal.
You should see it display an error saying "2024/06/12 09:32:01 Error occurred: task failed":

When you consistently log errors, you maintain a transparent record of occurrences, aiding in troubleshooting and enhancing application reliability.
Logging errors also helps in proactive monitoring and alerting. Through log analysis, you can discern patterns and trends indicative of impending issues, allowing for timely intervention and resolution, minimizing downtime, and improving the user experience.
Panic and recover
While Go's primary error handling mechanism relies on returning errors as values, the language also introduces panic and recover for exceptional conditions that cannot be addressed through regular error handling.
Panics are used for situations where the program encounters an unrecoverable error and cannot proceed normally. This mechanism is typically reserved for serious issues, such as programming bugs or critical failures. However, Go also provides the ability to recover from panics, allowing the program to regain control and potentially continue execution in a controlled manner.
How to use panic
A panic in Go is a built-in function that stops the ordinary flow of control. When a function panics, it immediately stops execution and starts unwinding the stack, executing any deferred functions along the way. If a panic is not recovered, the program will terminate and produce a stack trace, which is useful for debugging.
Here's an example of how to use panic in a Go program. Replace the code in main.go with the following code
Run the code using the go run command in your terminal.
Running this code however will cause a runtime panic when attempting to divide by zero. Specifically, the call to mustDivide(4, 0) will trigger a panic due to the division by zero, and the program will terminate abruptly without recovering from the panic.
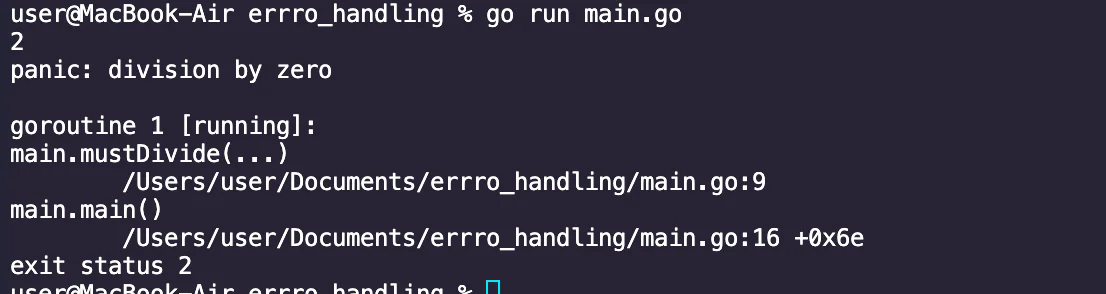
To handle this situation, that's where the panic mechanism comes in.
How to use recover
To handle a panic and allow the program to continue running, Go provides the recover() function. Recover is used within a deferred function to regain control of the program after a panic. By using defer to specify a function that will be executed when a panic occurs, recover can capture the panic and prevent the program from terminating.
Here's an example of how to use recover to handle a panic. Replace the main.go code with the following:
In this example, the mustDivide() function performs division and triggers a panic if the divisor is zero. The main function employs a deferred anonymous function to catch any panics that occur during its execution, logging the panic message and continuing execution afterward.
Run the code using the go run command in your terminal.
You should see it display this:

When to use panic and recover
Panic is best used for unrecoverable errors that indicate a program bug, such as out-of-bounds array access, nil pointer dereference, or other conditions that should never occur in correct code. Avoid using panic for regular error handling.
You can use recover to handle panics in situations where you need to clean up resources, log the error, or continue running the program despite a critical failure. Recover should be used in deferred functions to ensure that it captures panics effectively.
That's the essentials of error handling in Go
In this tutorial, we examined Go‘s approach to error handling by examining different error handling techniques. We also examined Go's panic and recovery mechanism in situations where exceptional conditions cannot be addressed through regular error handling.
Explicit error handling promotes clarity and reliability, helping you build maintainable applications in Go. By following these techniques, you are well on your way to handling errors effectively and ensuring your application is resilient to unexpected conditions.
Temitope Taiwo Oyedele is a software engineer and technical writer. He likes to write about things he’s learned and experienced.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.