Chaos Engineering at Twilio with Ratequeue HA
Time to read: 5 minutes
November 16, 2017
Written by

Twilio engineers are constantly working on improving our core services to meet or exceed 5 nines of availability. A system’s capacity for self-healing when a fault occurs is a key measure of achieving high availability. Recently, Twilio used Chaos Engineering to close the gap and eliminate the need for human intervention for common faults involving our core queueing-and-rate-limiting system, Ratequeue.
Background
Twilio empowers customers to make 100’s of concurrent API requests. However, your messages may be unexpectedly rate-limited, such as carrier regulations (US long codes), contractual limitations (US short codes), or technological (e.g. capacity). As a safeguard, Twilio automatically queues outbound messages for delivery. Each Twilio phone number gets a separate queue and messages are dequeued at rate depending on the contract.
Ratequeue
Ratequeue is an internally-developed distributed queueing system designed for simultaneously rate-limiting dequeue rates for many ephemeral queues. Each sender ID (e.g. phone number, short code, Alphanumeric ID) is given an ephemeral queue and contains all messages that are queued for delivery.
Ratequeue uses Redis as the main data store for creating and maintaining queues. We have horizontally partitioned our Redis data (also called sharding) by having each Ratequeue instance run its own local Redis store.
This means that data is isolated from each Ratequeue shard and when one shard fails, the data on other shards are not affected. Additionally, each Ratequeue shard is deployed with a primary and a replica so that we do not lose messages when hosts fail.
Problem
We had previously designed and developed a failover mechanism for when a Ratequeue primary node encounters an unrecoverable fault. However, an on-call engineer was still required to choose a replacement primary and initiating the replica promotion. This is time consuming and introduces the risk of human error to this critical service in the Programmable SMS stack.
Failover
When a Ratequeue primary host fails, upstream services can still successfully enqueue messages on the unaffected Ratequeue primary shards. However, messages that were queued within the failed Ratequeue primary shard are not serviced until a replica is promoted to replace the failed primary. When healthchecks start failing for a primary host, an on-call engineer is paged to begin the failover process. The on-call engineer then begins a number of steps:
- Wake up, stumble out of bed, find laptop, and try snap out of a sleep haze to connect to the VPN
- Look at runbooks, debug issue
- Find the Ratequeue replica host that has the same shard number as the primary
- Run the promotion task on the replica host
- Shutdown old primary
- Put the promoted replica (new primary) into load balancer
- Boot a new replica
- Congrats, Ratequeue cluster is healed, back to sleep.
While the failover steps itself are not very complicated, it is still a manual process done by the on-call engineer which introduces room for human errors. This process can take 20 minutes or more for a human to debug and recover the cluster, causing messages to be delayed for a long period of time.
Ratequeue High Availability (HA)
Since Ratequeue is a critical service, the team recognized automating the failover as a high priority, so we put a plan in motion to solve this.
Coming into this project, we had 3 system design goals in mind.
- Detect primary host failure
- Promote a replica if primary is likely down
- If we determined the primary to be down, but it’s really not (network partitions, etc), the primary will automatically go into a draining mode when out of load balancer and enqueue it’s items to other healthy shards.
- Don’t lose data.
We evaluated a number of proposals and proof of concepts using Redis sentinel but we had difficulty accomplishing design goal number 3 due to the way we’ve designed Ratequeue. After a network partition, sentinel wipes the data from the old (demoted) primary and syncs it to the new primary, but we need this data for the draining mode when the network heals. We decided on a custom solution which leveraged a number of pre-existing Twilio services to accomplish automated failover:
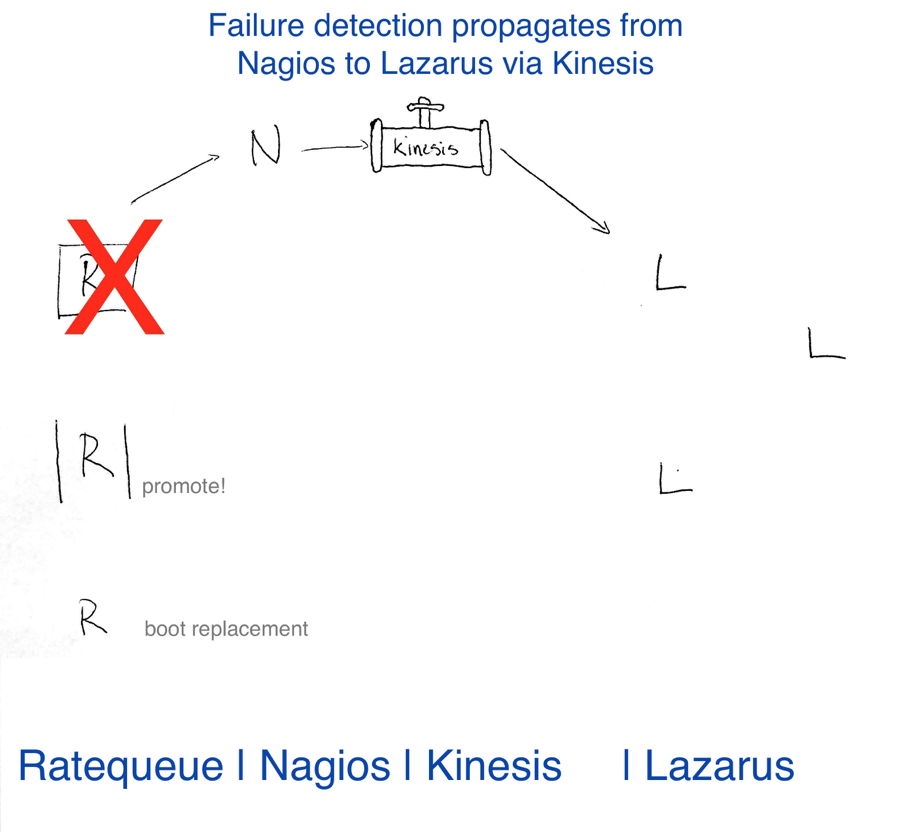
- The Ratequeue replica box pings the health check on the corresponding primary host every 10 seconds and publishes the result of the healthcheck to our Nagios server.
- When Nagios receives 3 failures from the replica host, it publishes a notification to Amazon Kinesis.
- Our cluster automator service, Lazarus, dequeues events from Kinesis, validates the events and the state of the entire cluster, and then executes a specified workflow to remediate the failed host.
- Our workflow “Replace Host with Standby Promotion is executed.” This workflow consists of:
- Identifying the shard that failed
- Finding the in load balancer replica host with the matching shard
- Calling promote task on the replica host
- Booting a new Ratequeue replica host with the same shard tag.
With this system, we were able to achieve all three system design goals and detect failure in just ~30 seconds. The complete automated failover completes in a little over a minute!
Testing Ratequeue HA
After implementing Ratequeue HA, we needed a way to validate that failures were being detected and recovered properly. To accomplish this, we designed a tool called Ratequeue Chaos.
Ratequeue Chaos has 3 goals:
- Pick a shard
- Kill primary
- Monitor recovery.
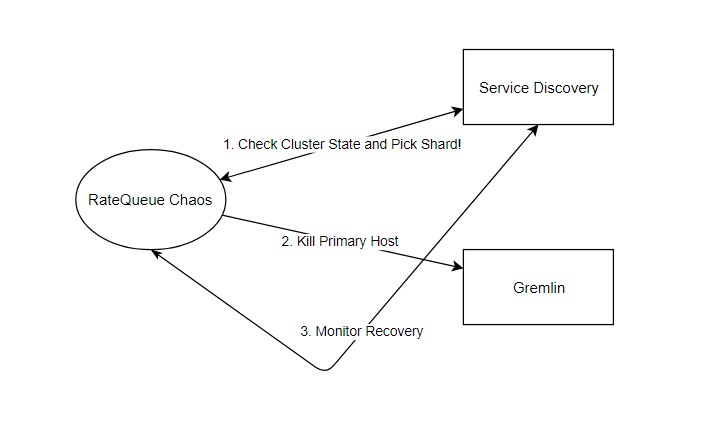
Ratequeue Chaos uses our service discovery system to obtain information regarding the state of the Ratequeue cluster. It ensures that there are at least 2 healthy shards of Ratequeue running before picking one of the shards.
All hosts in our dev and stage environment run a service called Gremlin. Gremlin is a “Failure as a Service” fault injection tool created by the team at Gremlin, Inc, engineers who previously built chaos engineering tooling for Amazon and Netflix. Gremlin provides an extremely simple to use API for setting up automated fault injection testing on your services with different sets of attacks as listed below:
- Shutdown
- Blackhole
- Latency
- Dns
- Packet loss
- CPU
- Memory
- IO
Ratequeue Chaos starts a shutdown attack using the Gremlin API on the selected shard’s primary host. Gremlin’s API tells us the attack started successfully, and Ratequeue Chaos begins to monitor for the failover process. Using our service discovery, we monitor and wait for the failed primary host to exit the load balancer. Next, we monitor the new Ratequeue primary (promoted replica) to enter the load balancer. When the new primary enters the load balancer, the Ratequeue cluster is now deemed healthy.
We run Ratequeue Chaos in our staging environment every 4 hours and have had great success catching bugs that we did not anticipate.
Successful Chaos Engineering
The key to a successful chaos engineering test is to have a hypothesis you’d like to test. In our case, we wanted to see if Ratequeue would self-heal if a primary host shut down. It’s a simple test we can run to see if the system is resilient or if we need to go back and fix some couplings.
The next thing you need is to have a framework to measure your tests. It’s important to have a performance metric that you’re looking to improve. In our case, it’s availability of Ratequeue without human interaction.
Finally, you need to have a rollback plan. In this instance, we’re running Ratequeue Chaos on staging. If Ratequeue Chaos detects a failure in our staging environment, we can have an engineer manually intervene without impacting our customers. If you run tests in production you’ll want to have a plan to revert to normal state.
With the increasing complexity and unpredictability of distributed systems that the industry is adopting, we highly recommend practicing chaos engineering wherever possible to test for coupling and increase your system’s resilience. After implementing Ratequeue High Availability and Ratequeue Chaos, we saw our first automated failover in production a few months ago complete in a little over a minute. We are confident that we can lose one of these shards at any point.

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.