Text to speech in the browser with the Web Speech API
Time to read:
August 22, 2019
Written by

The Web Speech API has two functions, speech synthesis, otherwise known as text to speech, and speech recognition. With the SpeechSynthesis API we can command the browser to read out any text in a number of different voices.
From a vocal alerts in an application to bringing an Autopilot powered chatbot to life on your website, the Web Speech API has a lot of potential for web interfaces. Follow on to find out how to get your web application speaking back to you.
What you'll need
If you want to build this application as we learn about the SpeechSynthesis API then you'll need a couple of things:
- A modern browser (the API is supported across the majority of desktop and mobile browsers)
- A text editor
Once you're ready, create a directory to work in and download this HTML file and this CSS file to it. Make sure they are in the same folder and the CSS file is named style.css. Open the HTML file in your browser and you should see this:
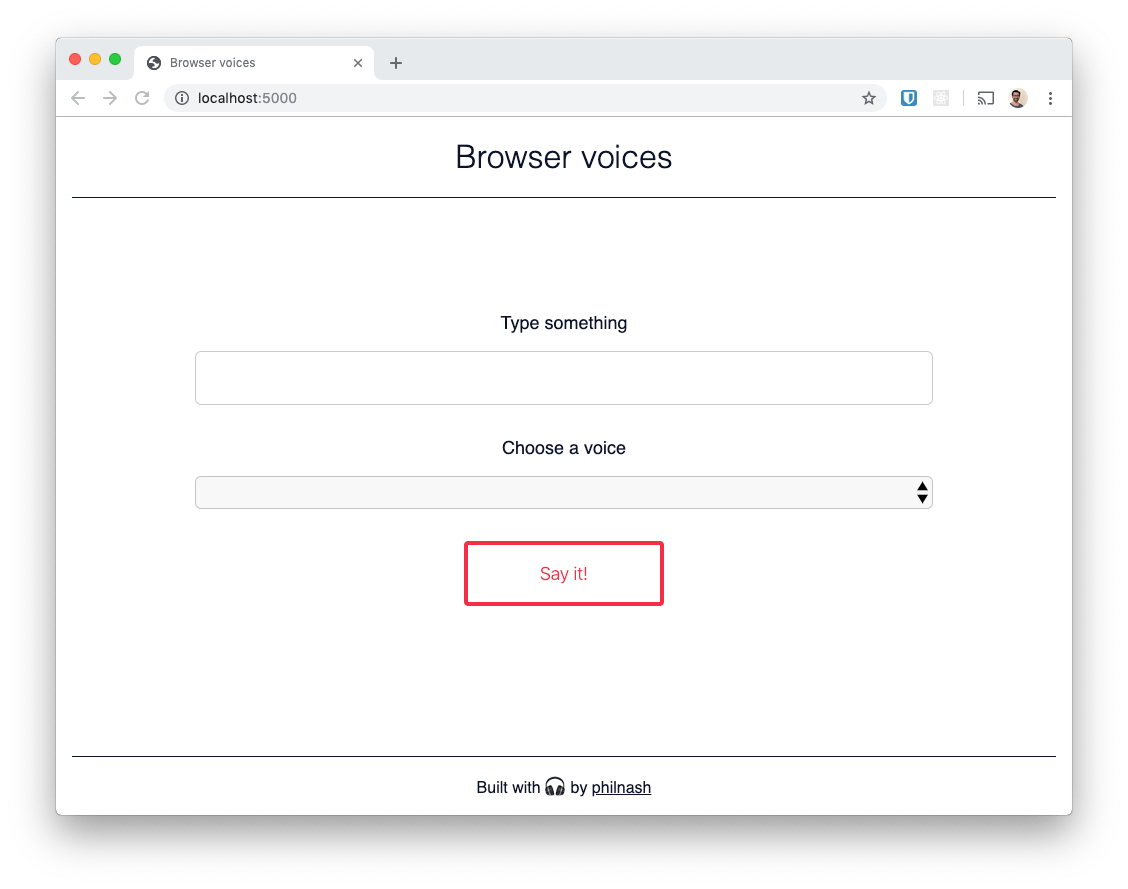
Let's get started with the API by getting the browser to talk to us for the first time.
The Speech Synthesis API
Before we start work with this small application, we can get the browser to start speaking using the browser's developer tools. On any web page, open up the developer tools console and enter the following code:
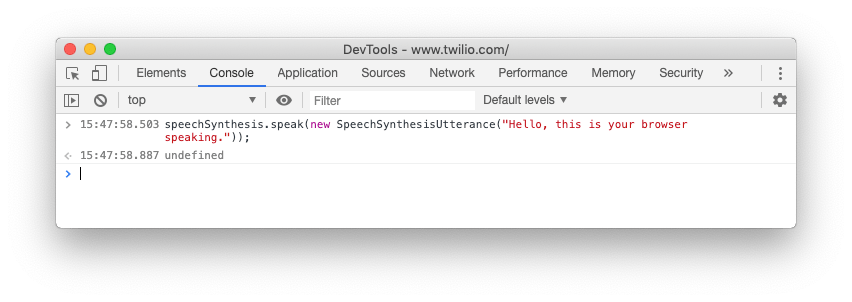
Your browser will speak the text "Hello, this is your browser speaking." in its default voice. We can break this down a bit though.
We created a SpeechSynthesisUtterance which contained the text we wanted to be spoken. Then we passed the utterance to the speak method of the speechSynthesis object. This queues up the utterance to be spoken and then starts the browser speaking. If you send more than one utterance to the speak method they will be spoken one after another.
Let's take the starter code we downloaded earlier and turn this into a small app where we can input the text to be spoken and choose the voice that the browser says it in.
Speech Synthesis in a web application
Open up the HTML file you downloaded earlier in your text editor. We'll start by connecting the form up to speak whatever you enter in the text input when you submit. Later, we'll add the ability to choose the voice to use.
Between the <script> tags at the bottom of the HTML we'll start by listening for the DOMContentLoaded event and then selecting some references to the elements we'll need.
We then need to listen to the submit event on the form and when it fires, grab the text from the input. With that text we'll create a SpeechSynthesisUtterance and then pass it to speechSynthesis.speak. Finally, we empty the input box and wait for the next thing to say.
Open the HTML in your browser and enter some text in the input. You can ignore the <select> box at this point, we'll use that in the next section. Hit "Say it" and listen to the browser read out your words.
It's not much code to get the browser to say something, but what if we want to pick the voice that it uses. Let's populate the dropdown on the page with the available voices and use it to select the one we want to use.
Picking voices for text to speech
We need to get references to the <select> element on the page and initialise a couple of variables we'll use to store the available voices and the current voice we are using. Add this to the top of the script:
Next up we need to populate the select element with the available voices. We'll create a new function to do this, as we might want to call it more than once (more on that in a bit). We can call on speechSynthesis.getVoices() to return the available SpeechSynthesisVoice objects.
Whilst we are populating the voice options we should also detect the currently selected voice. If we have already chosen a voice we can check against our currentVoice object and if we haven't yet chosen a voice then we can detect the default voice with the voice.default property.
We can call populateVoice straight away. Some browsers will load the voices page load and will return their list straight away. Other browsers need to load their list of voices asynchronously and will emit a "voiceschanged" event once they have loaded. Some browsers do not emit this event at all though.
To account for all the potential scenarios we'll call populateVoices immediately and also set it as the callback to the "voiceschanged" event.
Reload the page and you will see the <select> element populated with all the available voices, including the language the voice supports. We haven't hooked up selecting and using the voice yet though, that comes next.
Listen to the "change" event of the select element and whenever it is fired, select the currentVoice using the selectedIndex of the <select> element.
Now, to use the voice with the speech utterance we need to set the voice on the utterance that we create.
Reload the page and play around selecting different voices and saying different things.
Bonus: build a visual speaking indicator
We've built a speech synthesiser that can use different voices, but I wanted to throw one more thing in for fun. Speech utterances emit a number of events that you can use to make your application respond to speech. To finish this little app off we're going to make an animation show as the browser is speaking. I've already added the CSS for the animation so to activate it we need to add a "speaking" class to the <main> element while the browser is speaking.
Grab a reference to the <main> element at the top of the script:
Now, we can listen to the start and end events of the utterance to add and remove the "speaking" class. But, if we remove the class in the middle of the animation it won't fade out smoothly, so we should listen for the end of the animation's iteration, using the "animationiteration" event, and then remove the class.
Now when you start the browser talking the background will pulse blue and when the utterance is over it will stop.
Your browser is getting chatty
In this post you've seen how to get started and work with the Speech Synthesis API from the Web Speech API. All the code for this application can be found on GitHub and you can see it in action or remix it on Glitch.
I'm excited about the potential of this API for building my own in browser bots, so look out for more of this in the future.
Have you used the Speech Synthesis API or have any plans for it? I'd love to hear in the comments below, or drop me a note at philnash@twilio.com or on Twitter at @philnash.


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.