Orchestrate a Twilio Webhook Deployment to AWS EC2 Using Ansible
Time to read: 23 minutes
October 13, 2020
Written by

Suppose you have a Flask application handling a Twilio webhook of yours. For instance, one which saves an SMS or a recording of a Twilio phone call to some cloud storage or a database. For a production deployment of your webhook you would likely want to spin up a virtual machine instance in a cloud server provider, such as EC2 on AWS. But that can quickly become too cumbersome and error-prone to handle manually, especially when upgrading the application, or if you want to do some complex cloud storage schema.
In this tutorial, we will demonstrate how to use Ansible, an open-source orchestration tool, to deploy a Twilio webhook on EC2 in a maintainable and extendable manner. First we will go through core Ansible concepts, then we will write a simple Flask application (our webhook) and explain how to serve it, then we will cover provisioning an EC2 instance using Ansible, and finally tie it all together in a single Ansible playbook which we will use for provisioning a server and deploying our webhook.
Tutorial Requirements
- A UNIX-based computer. If you have a Windows computer, you can use WSL.
- Python 3.5 or newer (some Linux distributions like Debian and Ubuntu don’t include venv and pip with their default Python installs, so install python3-pip and python3-venv if you haven’t already)
- An AWS account, for spinning up EC2 servers. If you don’t have an account, you can create one now and enjoy a generous allowance during your first year.
- An account on a Git platform (GitHub, GitLab etc.)
- A Twilio account and a number. If you are new to Twilio, create a free account now. You can review the features and limitations of a free Twilio account here.
- A mobile phone with an active phone number
Orchestration
If you are not familiar with the concept of orchestration, here is a short introduction. Orchestration is a set of procedures for managing many (typically remote) hosts, with the goal of simplifying the administration of some arbitrarily complex system. Below are a few use cases for orchestration.
Web application
Serving a web application usually consists of serving three components:
- the front end, which controls the layout and the behaviour exposed to the end user; it is usually being run on the client computers, through the browser;
- the back end, which implements the application logic, including database access and authentication; and
- the database, which serves data for the back end to consume and for the front end to present to the end user.
Web apps are often set up in a way which separates these three components across multiple hosts (be it Docker containers, virtual machines or dedicated bare-metal machines). Furthermore, if the app is aimed at a global audience, then it is likely that there will be several replicas of these servers for each of the targeted regions (e.g. Europe East/West, Russia, USA), both to reduce latency and configure regional settings (e.g. timezone, local currency). Finally, any serious project is likely to have multiple environments set up: one for production use (the only one exposed to users), and at least one more for developing and testing new features (typically only exposed to developers).
Omitting the regional and many other considerations, we have already hit a minimum of 6 servers - but likely a lot more. Clearly, managing (e.g. updating, controlling access, or monitoring) such a system "by hand" would be very slow, prone to mistakes, and hard to follow - simply put, very problematic. It is, thus, desirable to have some smarter way to manage the system.
Administering computers in a laboratory
Different laboratories in a STEM institute are likely to have different computational requirements, such as:
- GPUs for training deep learning models,
- software and hardware for simulating protein folding,
- software for annotating cancer cells on microscopic images of tissues.
Each of these server groups has some common denominator, so it would make sense to try to administer each group collectively, instead of individually, to ensure each server in the same group has the same environment.
IoT - smart homes
Once you buy a Raspberry Pi, several Arduino boards, various sensors (e.g. temperature and humidity), cameras and smart lighting components and set them all up in your home, the next step is to set up a system for managing all the various components. It is probably clear by this point where this is going: the boards controlling cameras, the boards controlling the weather station, and the boards controlling the lighting could all be grouped and administered collectively.
Ansible
Orchestration tools such as Redhat's Ansible, as well as more general cluster management tools (like Google's Kubernetes or Hashicorp's Nomad), offer tools to help with the situations laid out above. In this article we will cover Ansible because it is by far the most simple to set up, understand, and use. So let us go over some key concepts in Ansible.
Installation
Before doing anything with Ansible, we need to install it. Simply install the package ansible either through your package manager, or through pip:
Note that you may need to use sudo for this if you’re installing it globally, i.e. outside of a virtual environment. If you don’t know what virtual environments are, keep reading - they’re described a bit later. This also works on Windows when using WSL.
And that’s it! If you then hit ansible --version, you should see Ansible’s version message. That means you’re all set!
Overview
In Ansible, there are two kinds of nodes involved:
- managed nodes - e.g. the servers which serve the back end of a web app, and
- controller nodes - the nodes which initiate actions (e.g. installing and starting a database) on the managed nodes.
Typically, Ansible's workflow is this: when an action (called a play) is started on the controller node, it establishes an SSH connection with all concerned managed nodes and tries to perform the play (consisting of well-defined tasks) which should put the system in a desired state. Once the play ends (successfully or otherwise), a report is printed on the controller node.
Before going on, we should cover the basic Ansible terminology.
- Module - the smallest unit of work Ansible handles. A module is a Python script which Ansible will try to run on managed nodes, in order to perform a specific task. For example, the
gitmodule can pull the latest version of an application from a Git repository, theaptmodule can install packages through apt, and themailmodule can send an email. All of the modules are open-source, so their source code is available, and custom modules can be written. - Task - a wrapper around modules and the smallest unit of work in a play. A task defines the module to run and the nodes to target (e.g. the database servers). It can also include module arguments (e.g. the name of an apt package), the name of the user which should run the task, variables, etc.
- Play - a well-defined list of tasks to be run in sequence. A play is usually some larger logical unit of work, such as the whole deployment pipeline, which may consist of ensuring all needed packages are installed on the target machines, fetching code through Git, running tests, and starting the web app process if nothing fails.
- Playbook - a list of plays. A playbook typically consists of several plays which are related in some way (e.g. user management, setting up the database, deployment, notifying all involved parties via Telegram).
- Inventory - a file containing a list of managed nodes. In addition to simply listing nodes, any node groups, group-specific or global variables are defined here.
Ansible is agentless
In essence, the controller node opens connections to remote machines and then performs the requested actions through Python scripting (Ansible modules are implemented as Python scripts). This means that there are only two prerequisites to using Ansible: the ability to open a connection on target nodes, and the ability to run Python code on the target nodes (which is a reasonable assumption, at least on Unix machines). Therefore, we can conclude that Ansible is agentless - no Ansible-specific installations are needed on the managed nodes. Pretty convenient.
Application
Now that we have acquainted ourselves with Ansible, we can create a Flask application that will serve as a webhook. Let’s keep it simple - the app will have just a single endpoint: /receive_sms.
When an SMS message arrives to our Twilio phone number, Twilio will forward it to this endpoint (once we configure the number to do so, of course), which will simply return a greeting in the form of a TwiML (Twilio Markup Language - XML-structured data) response.
Virtual environment
Before doing anything, we need to create a virtual environment, or virtualenv. Virtualenvs are a construct that creates an isolated environment which does a couple of things that make life easier:
- makes sure that the correct version of Python (specified upon creation of each virtualenv) is being used,
- makes sure that the correct version of pip is being used,
- through some clever symlinking, ensures that the packages installed through pip are installed only in that environment,
- if you create virtualenvs in a place where you have permissions to create files and directories, you won't need
sudoto install pip packages.
So let's get to it! Let's create a project directory, and create a virtual environment called sms-venv in it using Python's built-in module venv:
Once that's done, the virtual environment has been created, and we can activate it by running the Bash script generated by venv:
The sms-venv in parentheses at the start of the prompt indicates that we have activated the virtualenv, so we can start working on the application. Running pip freeze (to list the installed pip packages) from inside the environment should output nothing - indicating that there are no packages. That’s good - we want a clean environment. We will install all needed packages right now, so we don’t miss anything:
flask- the Flask framework, for creating a web application,twilio- the Twilio Python Helper library, for working with Twilio APIs,python-dotenv- the Python Dotenv library, which helps with importing environment variables from files, andgunicorn- the Green Unicorn, a Python WSGI server.
You can install the packages inside the virtual environment like this:
Application code
First off, open a new the file named .flaskenv (note the leading dot), which will contain the required environment variables, and add the following variable:
In order for the variables to be imported automatically, we have the package python-dotenv, which we just installed.
In this case, we have only one environment variable. The FLASK_APP variable points to the file which will run the application. Let's create the sms-greeter.py file right now:
And that's it. All this does is import the webhook_app variable from the app Python package that we are about to write.
Now for the application logic. In the same directory, create a directory called app/, and then create a file called __init__.py inside it with the following content:
Note the very first import: we are importing Flask from the flask package, which we had installed above. In short, this file creates a Flask object, which represents the application, and then it imports the routes, or our endpoints, which we will define in app/routes.py. You can see the contents if this file below:
Note the last import: from twilio... - again, this is not a built-in library, but the official Twilio Python package we had installed above. From the library, we will use only the MessagingResponse class.
The rest of the file contains the definition of the receive_sms endpoint, our webhook. It accepts only HTTP POST requests, which Twilio will send each time an SMS message is received on the phone number. We still need to point Twilio to our webhook - we will cover this shortly.
When an event we are interested in occurs (e.g. an SMS or a call to our Twilio number), Twilio will make an HTTP request to the webhook we provide (in this case, our Flask app), and, more importantly, it will expect a TwiML response from it. These are XML responses, but we don't have to worry about structuring them manually - we have the MessagingResponse class to handle that for us!
In this case, we will obtain the sender’s number, create a message containing their number, and send it back as a TwiML response. You can find more details about responding to messages here, and all the SMS data fields available through Twilio can be found here.
Tracking the dependencies
Finally, we need to create a requirements.txt file which will list all the packages pip needs to install. It's simple: in the root directory (the one with sms-greeter.py), run the command pip freeze -l > requirements.txt. This usually resides in the root project directory, so the one with sms-greeter.py in this case. This will create a list of all the pip packages in the virtualenv and output it to the requirements.txt file.
If you want to install all necessary packages in one command, you can do so by running the command pip install -r requirements.txt. Our Ansible playbook will do the equivalent of this - that’s why we need this file in our project.
Testing the app locally
Now that we're done with the app, we should test it locally, to eliminate any bugs with handling the incoming data. We will test the app by sending a POST request through cURL, the command line HTTP client.
To run the app, run the following command from inside the virtual environment:
flask run &
Note the '&': it tells the terminal to run that process in the background, leaving the terminal free for new input. Once done, you can exit the process by putting it into foreground by running fg, and then hitting Ctrl+C.
There are addons which allow browsers to send POST requests along with the usual GET requests, but we will use cURL to send a POST request containing an example SMS:
curl -X POST -F 'From=test_number' -F 'Body=Hello this is a test SMS' localhost:5000/receive_sms/
The -X flag specifies the HTTP request type (POST), and the -F flag specifies a "form" field - the "From" and "Body" fields of an SMS. The output of running the command should look like this:
The response greeting picked up our “From” field, “test_number” - it looks like everything is okay! We can continue with deploying our app.
Running the application via services
Running a Flask built-in server is fine during development, but is not recommended in production, because it cannot easily be integrated into e.g. a Systemd service, cannot easily be reliably served along with other applications, cannot easily balance the load, and is just not robust enough.
Therefore, in practice, we use a combination of Nginx and Gunicorn. Nginx is an HTTP server that is extremely popular. It is fast, reliable, highly customizable and scalable. It is often used as a reverse proxy, which means that it listens for all incoming HTTP requests, and then routes the requests to the appropriate applications (if there are more than one) or directories.
Gunicorn, on the other hand, is an application WSGI server. WSGI stands for Web Server Gateway Interface - a standard way of communication between a web server (e.g. Nginx) and a Python web application. It abstracts many infrastructure details away from the application, such as handling concurrency or load balancing. We won't be going into the details of using Gunicorn, but a simple use case should be enough to get you started.
So, in the next two sections, we will write a Systemd service for running the app through Gunicorn, and an Nginx configuration file. Note that neither Gunicorn nor Nginx should be running on your computer - we will use these configuration files on the EC2 instance. Everything in this section regarding Nginx and Gunicorn is just information about what Ansible will do when we write the playbook. Other than writing the files, you don’t have to handle Gunicorn and Nginx manually. Ansible will do it for you.
Running Gunicorn
It is simple to use Gunicorn with Flask: simply pass the application module (the directory with the __init__.py file, in our case app) and the name of the Flask object (in our case, webhook_app, defined in __init__.py) to Gunicorn. The Flask object is significant because it implements the WSGI callable, so it can communicate with Gunicorn.
You could also specify the ports, the number of workers, threading details, log storage etc. So, to run the application on port 5000 using Gunicorn, you would use the following command:
where the -b binds the application to port 5000 on localhost.
Now that we know how to serve the application via Gunicorn, we should write a Systemd service file for it, so that we can manage it more consistently, and take care of detaching it from a terminal, restarting it if it dies, etc. There are plenty of resources on Systemd, so we won't go into details.
Let’s write the service file with the name sms-greeter.service in the main directory of the project. It should look like this:
The most important part is under [Service], where we set the working directory (our repository), and run gunicorn with the same flags as in the example above. Note that we're running gunicorn from the virtual environment, so you should specify its path. The final instruction, Restart=always, tells Systemd to restart the Gunicorn server every time it stops, whether through an error or when a process is killed for some reason.
There are many details about running Systemd services, but generally, service files are installed in /lib/systemd/system/ (this varies depending on the operating system). Everything regarding Systemd should be managed using systemctl.
Should you run into trouble when deploying the services, knowing the basics of Systemd service management will come in handy. Take a look at the following commands:
These are somewhat self-explanatory - they start/stop a service. Particularly useful for debugging are the commands:
The first one will show the status of the service and the last couple of logs. This is sometimes enough for debugging, but usually we will want more detailed logs, which can be found by the second command - journalctl is Systemd's tool for handling service logs. Hopefully you won't need it, because we will use Ansible for handling the service, but if you misconfigure something and the service fails to start, systemctl status should be your first stop.
Running Nginx
Once the Gunicorn service is running, we only need to point Nginx to it, so that it can route requests for our application to the application.
Nginx configuration consists of writing a configuration file, to define which ports to listen to, where to route specific requests, which static directories to serve etc. That configuration file then has to be added to /etc/nginx/sites-enabled, but in practice the files are added to /etc/nginx/sites-available, and the configuration files (usually one per application) we want enabled are then symlinked to the sites-enabled directory.
Write the configuration file sms-greeter.conf to the project directory. It should look like this:
Most of these options are extremely common and not that important to go into now. Let us just make a couple of remarks:
- the
locationblock will handle all requests which start with/sms/(e.g. http:my.site.example/sms/); - the
proxy_passin that block will tell Nginx to route such requests to the server running at localhost:5000/ (our Gunicorn server!); - for simplicity's sake we are setting up an HTTP server, but please always use HTTPS in production. It includes a little bit of work with certificates, but tools like Let's Encrypt make it easy. It is a bit out-of-scope to go into now, though.
Uploading to Git
Just one more step: we must push the application to a git repository, so that Ansible can pick it up later for deployment. Create an empty repository on a Git platform of your choice (GitHub, GitLab etc.) through the browser, and then in your project directory, run the following commands:
You could just write git add . to add everything in the directory, but if you ran the app locally, you likely have created some __pycache__/ directories which would only clutter the repository. Check out gitignore, git’s mechanism for dealing with files we don’t want tracked in a repository.
Twilio webhook URL configuration
Given that we will have a publically available server to host the app, we could run the app, get the URL of the post endpoint, and then log into the Twilio console and manually configure the Twilio number to set the webhook URL by copy-pasting. But since we're using an orchestration tool to automate the deployment of the webhook, why not go all the way and automate this webhook URL configuration as well?
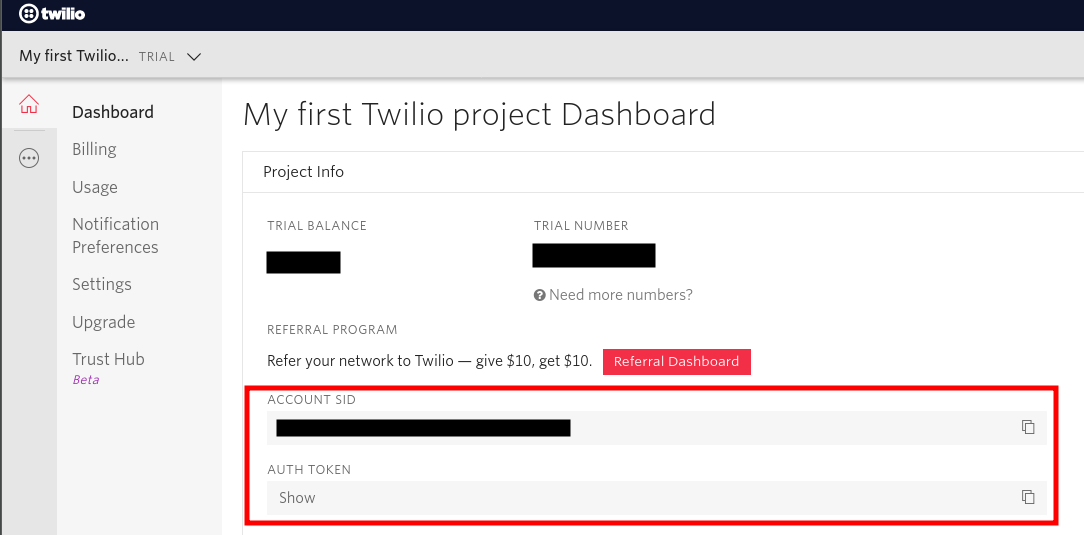
You will need your Twilio account credentials (your account SID and your authorization token) and the phone number SID to do this. You can find the credentials in your Twilio account console, as shown in the screenshot below. The credentials are in the red rectangle. It goes without saying that the auth token should be secret, so don’t share it with anyone!
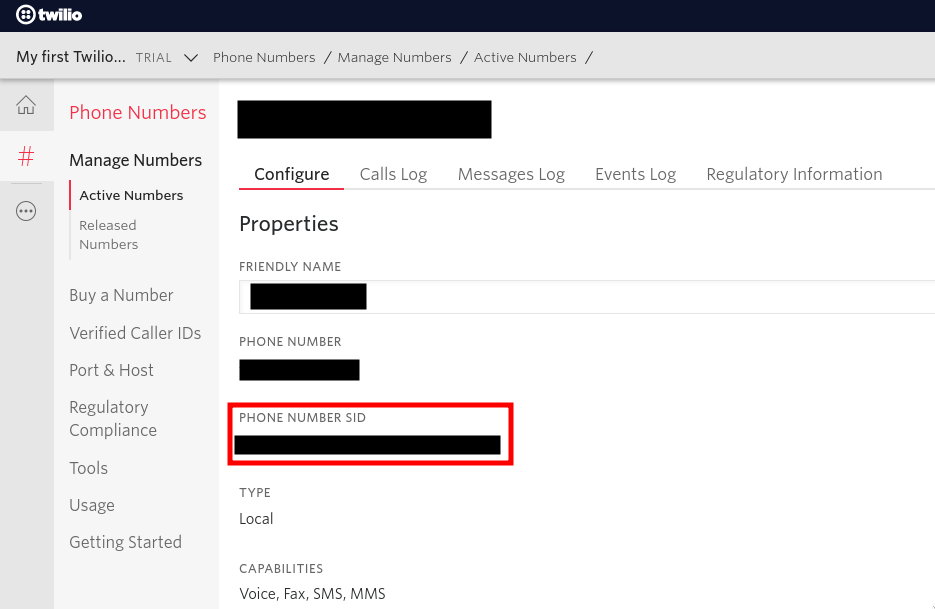
As for the phone number SID, you can find it on your phone number dashboard: choose a number you want to use the webhook with, and you should see the SID, as shown in the screenshot below.
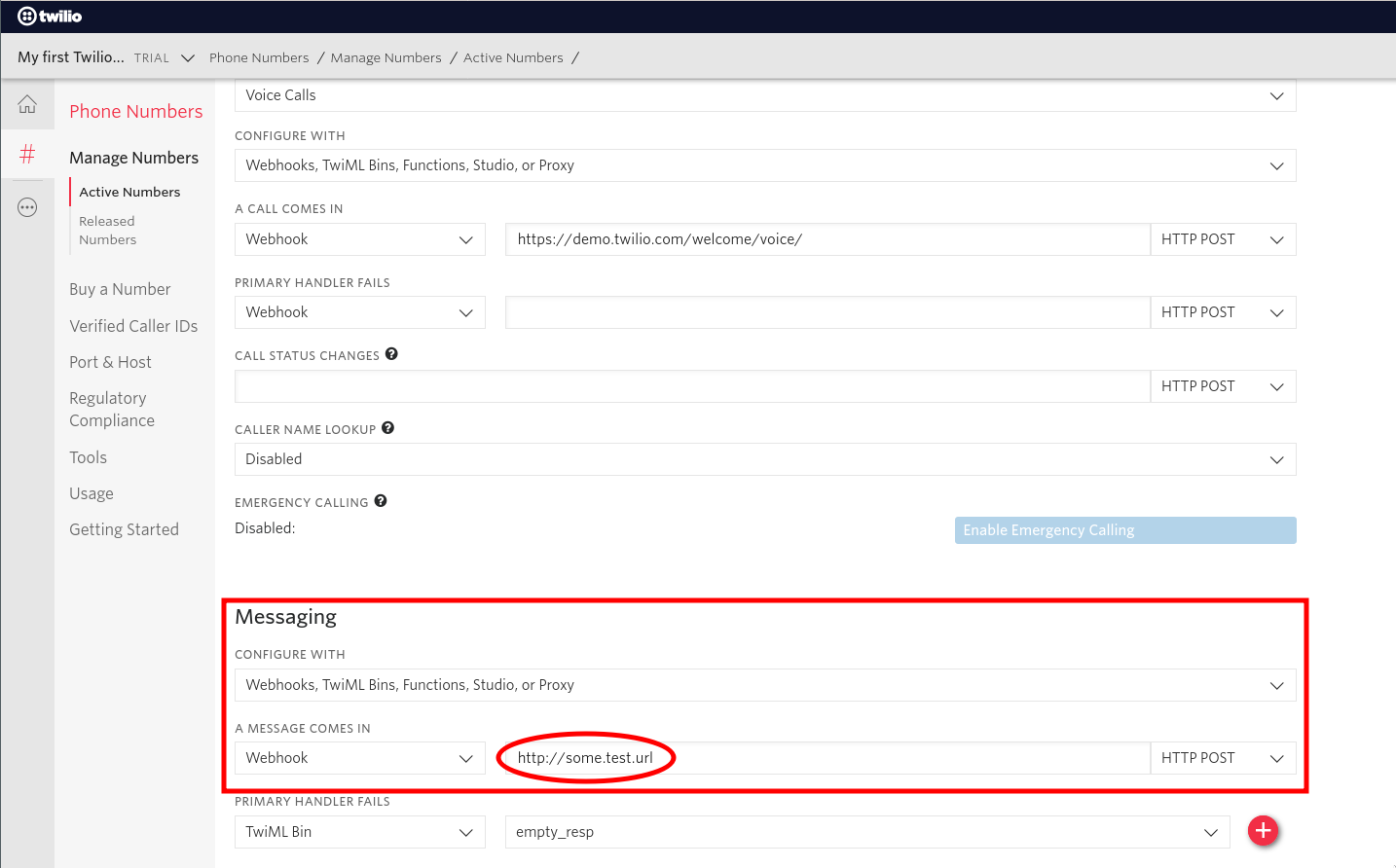
Once you’ve obtained your credentials, you will be able to programmatically configure the webhook URL for your Twilio number. This is possible with a simple POST request to one of Twilio's APIs: the Phone Numbers REST API, specifically its IncomingPhoneNumber resource. We will handle this in the deployment playbook a bit later, but if you want to convince yourself that it works, you can once again spin up cURL:
Once you get a response, you can go back to your phone number dashboard, select the number you’re working with, and verify that http://some.test.url has indeed been set as the Twilio webhook URL for SMS messages.
Playbook
Provisioning through Ansible
As outlined above, the "traditional" Ansible workflow is directed at remote hosts. But if we want to use Ansible for creating remote hosts, then such a workflow obviously won't work. Amazon's EC2 platform provides APIs for handling instances - including creating them. On the other side, Ansible provides the aptly-named module ec2, which enables us to easily work with EC2 APIs in playbooks.
So, we can point Ansible to localhost as a managed node, and then make use of that module to create an instance. Then we can collect the IP address of the new instance and do two things: treat the instance as a new managed node (to target it for webhook deployment), and dynamically configure the webhook URL, as mentioned earlier.
So let's break the playbook down into two plays: one for provisioning, and the other for deploying the application. But before that, we should talk about localhost access, EC2 authentication, the inventory file, and handling secret data.
Accessing localhost in playbooks
When Ansible targets localhost, it can use a local connection instead of opening an SSH connection to itself. You could run an SSH server on your computer and run Ansible normally, but this has larger security implications, so it would be better not to do it. To use the local connection, you can specify the parameter connection: local at the beginning of each play that targets localhost. Therefore, the provisioning play should have that parameter set.
EC2 Authentication
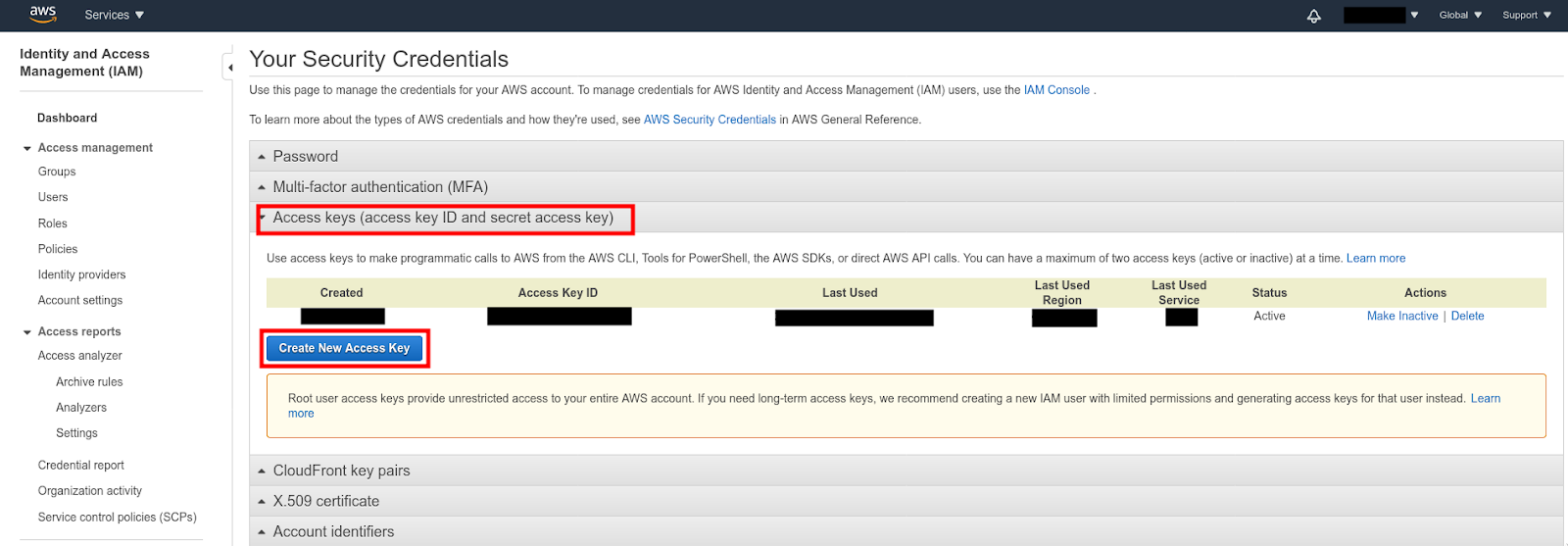
In order to communicate with the EC2 APIs, we need to obtain our AWS access key and secret key. So head on over to Amazon Web Services (AWS) and log in. If you don't have an AWS account yet, create one now.
Once logged in, click on “My Security Credentials” in the top right corner. You can manage your access keys there, under the "Access keys (access key ID and secret access key)" tab.
Another thing we're going to need is the PEM private key for accessing the instances (once created) via SSH. You could create and download a key pair in the AWS Console manually (under “Network & Security” > “Key Pairs” in the EC2 section), and it would arguably be a bit easier, or even desired in some cases. But since we're automating everything in this tutorial, why not create a key pair with Ansible, using the ec_key module?
Inventory
The inventory file for this project is going to be simple. We will have one host (localhost) and one group (ec2hosts; initially empty since we're provisioning via Ansible). We will also define variables - vars - for handling the EC2 PEM key - its name and the path to the key, so that we can access these variables later in the playbook.
So, create a file called e.g. inventory with the following contents:
Normally, the group definition would also contain a hosts: collection (just how the group all has it), but we want this group to initially be empty because we will create the hosts and add them to the group dynamically. Since we’re defining the group, we might as well define some useful variables, to tell Ansible:
- which user to connect to over SSH when targeting
ec2hosts(ansible_user), - which Python interpreter to use (
ansible_python_interpreter; specified for both localhost and the groupec2hosts), and - where to find the SSH key for accessing members of the group
ec2hosts- the same value we defined under variableec2_key_path.
Note that Python 3 may reside on a different path on your system. You can find out where your Python 3 executable is by running the following command:
Also, note that Ansible has plugins for handling dynamic inventories in a more robust manner. But we will not get into the details of that because it is a bit out of scope. If you want to know more, check out inventory plugins.
Handling Secrets
Before hitting the playbook, there is one more thing to cover: handling secret data. There are two secrets we will use: the AWS secret key, and the Twilio auth token. We could store them in a variable directly in the playbook, but that would prevent us from (responsibly) storing the playbook file under source control.
Luckily, Ansible ships with a tool for encrypting secrets, called Ansible Vault. It is easy to use, and very flexible. For brevity, we will cover just the most basic functionality and encrypt the secrets in the terminal. Then we will copy their encrypted versions to the playbook and let Ansible know that it's a Vault-encrypted variable. To do this, run the following command for each of the secrets you want to encrypt:
You will be prompted for a new Vault password, for its confirmation, and then for the secret itself, where you should copy the secret (in this case, the AWS secret key). Note: when you enter the secret, do not hit “Enter”! This would add a newline character to the secret (if it should contain a newline character, then by all means, hit “Enter”). Instead, terminate the input by hitting Ctrl + D two times.
In the output you will see something like the following:
which, as you would expect, contains your encrypted secret! Note the !vault at the beginning - that's Ansible's way of signifying that the variable is encrypted. It is then safe to paste this into your playbook. Do the same for the Twilio auth token:
Provisioning Play
Finally, it's time to start writing the playbook! Every code snippet from here to the end of this section can be in the same file (named provision_and_deploy.yaml), but as we write tasks, we should take time to understand them.
This is the beginning of the first play. We must provide the targeted hosts. Additionally, to make things easier, we define several variables (all entries under vars) which are defined in the scope of this play (but not the other one!). Note that there are several secrets here (AWS secret key and Twilio auth token), so make sure to encrypt them first using Vault, or use another solution for handling secrets.
Note the line gather_facts: false. This disables Ansible's feature of gathering facts about the managed hosts (everything from IP addresses to disk partitions). We won't be using this, and it can take some time, so we will disable it.
Regarding the AWS regions, you can find the available regions here.
Now that we've defined our variables, let's start writing tasks. There is no need to go into the details of each module we use - we have the official documentation for that, and the task names should describe the task in short - so we will stop only when needed.
Initially, all EC2 instances come with some pretty restrictive security settings. In order to access it via SSH or HTTP(S), we must then allow traffic through some ports on the instances. We can do that by creating a security group called twilio, and then placing the new instance into that group upon creation.
Note the line register: twilio_ec2_key. This tells Ansible to store the output of running the module ec2_key (a JSON with the key details, including the private key if the key has just been generated) to a variable called twilio_ec2_key. We can then access this variable to get the private key in the next task.
Also note that the next task ("Save private key") will be run only if the value of twilio_ec2_key.changed is true, that is, only if the key has just been changed (in this case, created). Otherwise, Ansible will simply skip the task. You can find this attribute, and all other attributes of the JSON response, in the documentation.
Now we can finally provision the EC2 instance. For completeness' sake, we will go through some of the options here. Again, note that the information about all the possible options is available in the documentation - and there really are plenty of options there.
instance_typespecifies the type of EC2 instance with regard to hardware requirements. Here, we are using one of the lightest ones available, because it's the cheapest and is more than enough for our current needs. Find more information here.imagespecifies the OS image (or AMI - “Amazon Machine Image”) to use - in this case, an Ubuntu 18.04.1 image: ami-0d359437d1756caa8. Find more information here.instance_tagsspecifies the tags, or labels, which we want to apply to the instance;exact_countspecifies the total amount of instances with the tags specified incount_tagwhich should be running after this task is done. In this case, we want exactly one instance, so if there already is an instance with the tag "Name" set totwilio-webhook, Ansible will do nothing.
We registered the output of the provisioning task to the variable ec2. In the next task, we are dynamically populating the inventory by looping (loop: ) through all tagged instances (even though we have just one - done just for demonstration purposes), getting their public DNS names, and adding them to the group ec2hosts. Once we do this, the provisioning part is done. However, we will add one more task to this play:
Remember when we said we would dynamically configure the Twilio webhook URL for our phone number? Well, this task does it, and is equivalent to the cURL command we've shown earlier. Note that this time we're not looping through the instances - we've instead picked the first (and only) instance with ec2.tagged_instances[0].
And with that, the first play is done! If you'd like, you can run it with:
The flag --ask-vault-pass tells Ansible to first ask for the Vault password, so that it can decrypt the encrypted secrets.
The output should look something like this:
Looking at the output, the "ok" tasks were already in the desired state and no changes were made, and the "changed" tasks were successfully executed. Parts of the output have been omitted for brevity. At the end, there is a recap with the count of tasks with each status.
Deployment Play
Now that we have an EC2 instance to work with, we can start writing the deployment play.
Given that we've just created an instance in the previous play, it's probably still booting, so the SSH server is likely still not ready. Therefore, before moving on, we need to wait for the SSH server to start. We can use the module wait_for_connection for this. Remember that we have defined which SSH key we should use for communicating with machines from the ec2hosts group when we set the variable ansible_ssh_private_key_file in the inventory file.
The first two tasks simply install needed packages, and the third one pulls the project repository (or clones if it doesn't exist locally) from GitHub - specifically, the last commit on the master branch.
This task installs the required packages into the virtualenv at ~/sms-greeter, and creates the virtualenv if it doesn't exist already. Additionally, the Python version is specified.
These tasks handle the Gunicorn service we wrote earlier. First it copies the service file to the Systemd directory, and then makes sure it hits the state started, with the most recent version of the service file (as indicated by daemon_reload: true).
These three tasks handle nginx. We are dynamically provisioning the server, so it's not that important to symlink the config file from sites-available/ to sites-enabled/. Note the second task: it ensures that the default Nginx welcome page config is absent - it is unnecessary, and it can sometimes cause problems so it is easier to just delete it.
And there you have it, that's our play for deploying! You can just glue the pieces of this file together, enter your credentials and modify it to suit your needs. You can again run it using the same ansible-playbook command as above. We will omit the output of that command for the whole playbook because its interpretation is the same as for the provisioning part.
Conclusion
In this tutorial we have covered a lot of ground: the concept of orchestration, the basics of working with Ansible, provisioning with Ansible, writing a Twilio webhook in Flask, and then deploying it using Ansible. For your reference, here is the repository with all the files we created above. If you’ll be using this, just make sure that you put in your details (names, paths, credentials) where necessary.
However, there is still a lot of room for improvement, such as:
- setting up dev and prod environments,
- using HTTPS instead of HTTP,
- adding a teardown playbook for easier deployment from scratch,
- using a truly dynamic inventory,
- providing high availability by adding a load balancer and several instances of the app
and many other ideas. For high availability, you may want to spin up several instances in a cloud server provider, add some kind of load balancing, and run the application on each of the servers. However, now that you have multiple instances of your application deployed, your deployment process may be a bit cumbersome, and maintaining the application on each of the servers manually may quickly become a nightmare. In such a use case, Ansible would help immensely.
Hopefully this tutorial will get you started with using Ansible, because it is a really powerful tool that is simple to understand and has a great community!
Leonard Volarić Horvat is a computer science engineer who is a passionate open-source advocate, and enthusiastic about machine learning, mathematics, music, and demystifying computers for the general public. Get in touch at leonard.volaric.horvat@gmail.org or check out his projects at https://github.com/LVH-27.

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.