How to Build an AI Voice Assistant on WhatsApp with Python, Whisper API, ChatGPT API, and Twilio
Time to read:
May 23, 2023
Written by
Reviewed by

As the world becomes increasingly interconnected and reliant on technology, more and more businesses are turning to AI voice assistants to improve customer experience and streamline operations. One platform that has seen a surge in popularity in recent years is WhatsApp. With over 2.2 billion monthly active users, it's no surprise that many businesses are looking for ways to integrate AI chatbots, including AI voice assistants, into their WhatsApp chat systems.
We’ve seen how to build AI chatbots using Django and FastAPI. These chatbots were able to understand text messages coming from users through the Twilio Messaging API accessing WhatsApp and also were able to give intelligent responses via the OpenAI ChatGPT API. Today, you’re going to build an AI voice assistant that understands users’ voice notes through OpenAI's Whisper API and that replies intelligently to each voice note with a ChatGPT response.
At the end of this tutorial, you'll know how to build an AI voice assistant on WhatsApp using Python, Whisper API, ChatGPT API, and Twilio Programmable Messaging API.
You'll start by setting up the backend using FastAPI and SQLAlchemy to create a PostgreSQL database to store your customers' data. Then, you'll integrate Twilio's WhatsApp Messaging API, allowing customers to initiate conversations with your WhatsApp chatbot.
With Pyngrok, you'll put the FastAPI localhost on the internet through Python, making it accessible for the Twilio API to communicate with.
Finally, the core of this AI chatbot will be built using the Whisper API with the whisper-1 model, and ChatGPT API with the GPT-3.5-turbo model.
Prerequisites
To follow this tutorial, you will need the following prerequisites:
- Python 3.7+ installed on your machine.
- PostgreSQL installed on your machine.
- A Twilio account set up. If you don't have one, you can create a free account here.
- An OpenAI API key.
- A smartphone with WhatsApp installed to test your AI chatbot.
- A basic understanding of FastAPI, a modern, fast (high-performance), web framework for building APIs with Python 3.6+.
- A basic understanding of what an ORM is. If you are not familiar with ORM, we recommend you read this wiki page to get an idea of what it is and how it works.
- ffmpeg installed on your machine to be able to convert voice notes to the appropriate formats that Whisper accepts.
Setting up your development environment
Before building the chatbot, you need to set up your development environment. Start with creating a new virtual environment:
Here, you create the ai_voice_assistant directory and navigate into it. Then you create a new Python virtual environment using venv. Finally, you activate the environment and then upgrade pip, the Python package manager.
Next, create a requirements.txt file that includes the following:
Here is a breakdown of these dependencies:
fastapi: A package for FastAPI, a modern web framework for building APIs with Python 3.7+ based on standard Python type hints. It's designed to be easy to use, fast, and to provide automatic validation of request and response data.uvicorn: A package for Uvicorn, a fast ASGI server implementation, using the websockets library for long-polling connections, and based on uvloop and httptools.openai: A Python client for OpenAI, the research company that focuses on developing and advancing artificial intelligence. OpenAI offers various AI models, including the GPT-3.5-turbo model, which is used in this tutorial to power the chatbot.twilio: A Python helper library for Twilio, the cloud communications platform that allows software developers to programmatically make and receive phone calls, send and receive text messages, and perform other communication functions using its web service APIs.python-decouple: A library for separating the settings of your Python application from the source code. It allows you to store your settings in an environment file, instead of hardcoding them into your code.sqlalchemy: A Python library that provides a set of high-level APIs for working with relational databases. It allows developers to work with multiple database backends, including PostgreSQL, MySQL, and SQLite. In the context of building an AI voice assistant, SQLAlchemy can be used to store and manage user data, chat history, and other relevant information. We will use it to access PostgreSQL in this tutorial.psycopg2-binary: A Python package that provides a PostgreSQL database adapter for the Python programming language.python-multipart: A library that allows you to parse multipart form data in Python, which is commonly used to handle form submissions that contain files such as images or videos. In the case of this tutorial, it will be used to handle form data from the user's input through the WhatsApp chatbot.pyngrok: A Python wrapper for ngrok, a tool that allows you to expose a web server running on your local machine to the internet. You'll use it to test your Twilio webhook while you send WhatsApp messages.pydub: A Python library for working with audio files. It provides a simple and easy-to-use interface for loading, manipulating, and exporting audio files in various formats. You’ll use it to convert the OGG audio file coming from WhatsApp to an MP3 file, which is one of the formats that the Whisper API accepts.requests: A Python library for sending HTTP requests and working with web APIs. It provides a simple and intuitive interface for making HTTP requests and handling response data. You’ll need it to retrieve and download the audio file coming from WhatsApp.
Now, you can install these dependencies:
Configuring your database
You can use your own PostgreSQL database or set up a new database with the createdb PostgreSQL utility command:
In this tutorial, you will use SQLAlchemy to access the PostgreSQL database. Put the following into a new models.py file:
This code sets up a connection to a PostgreSQL database using SQLAlchemy and creates a table named conversations. Here's a breakdown of what each part does:
URL.createcreates the URL object, which is used as the argument for thecreate_enginefunction. Here, it specifies thedrivername,username,password,host,database, andportof the database.create_enginefunction creates an engine object that manages connections to the database using a URL that contains the connection information for the database.sessionmakeris a factory for creating Session objects that are used to interact with the database.declarative_baseis a factory function that returns a base class that can be subclassed to define mapped classes for the ORM.- The
Conversationclass is a mapped class that inherits fromBaseand maps to theconversationtable. It has four columns:id,sender,message, andresponse.idis the primary key column,senderis a string column that holds the sender phone number the message is sent from,messageis a string column that holds the message text, andresponseis a string column that holds the response message that will come from OpenAI. Base.metadata.create_allcreates all tables in the database (in this case, it creates the conversations table) if they do not exist.
So the goal of this simple model is to store conversations for your app.
Note: here, you've used decouple.config to access the environment variables for your database: DB_USER and DB_PASSWORD. You should now create a .env file that stores these credentials with their associated values. Something like the following, but replacing the placeholder text with your actual values:
Transcribing your first audio using Whisper
To be able to manipulate the voice notes coming from WhatsApp, you need to know what format the voice note audio is. Once you know that, you need to figure out a way to transcribe that audio to text.
You also need to know which kinds of audio files that the OpenAI Whisper API accepts as input. As documented in the OpenAI guide here, the following input file types are supported: mp3, mp4, mpeg, mpga, m4a, wav, and webm.
So you need to be able to convert ogg format to mp3 format as indicated in the following code snippet called transcribe.py:
Before you run the code, make sure to have the OpenAI API key in your .env file:
Also, make sure to create a new directory called data so that your OGG file will reside there and the exported file will live there as well.
I’ve uploaded a sample audio here of an OGG file so that you can convert and transcribe it practically. You can download it and put it in the data directory. So you can now change the input_file variable to this path instead: data/sample_audio.ogg.
You can run the code now using python transcribe.py on the terminal. You’ll see something like the following JSON containing a transcribed text of the MP3 audio that you passed:
Let’s break down what this code is doing.
This code transcribes an audio file using the OpenAI Whisper API. Specifically, it uses the openai.Audio.transcribe() method to transcribe an MP3 audio file encoded with the "whisper-1" language model, using a temperature of 0.5. The transcription result is then printed to the console.
Before transcribing the audio file, the code uses the Pydub library to load an audio file in OGG format from the path specified in the input_file variable. The audio file is then exported in MP3 format to a file specified in the mp3_file variable. Finally, the MP3 file is opened and passed as input to the openai.Audio.transcribe()` method.
You will use the previous code as a utility function in your FastAPI app. Now, you can start building your chatbot and integrate what you've done into WhatsApp.
Creating your chatbot
Now that you have set up your environment and created the database, it's time to build the chatbot. In this section, you will write the code for a basic chatbot using OpenAI Whisper API and Twilio Programmable Messaging API.
Configuring your Twilio Sandbox for WhatsApp
To use Twilio's Messaging API to enable the chatbot to communicate with WhatsApp users, you need to configure the Twilio Sandbox for WhatsApp. Here's how to do it:
- Assuming you've already set up a new Twilio account, go to the Twilio Console and choose the Messaging tab on the left panel.
- Under Try it out, click on Send a WhatsApp message. You'll land on the Sandbox tab by default and you'll see a phone number "+14155238886" with a code to join next to it on the left and a QR code on the right.
- To enable the Twilio testing environment, send a WhatsApp message with this code's text to the displayed phone number. You can click on the hyperlink to direct you to the WhatsApp chat if you are using the web version. Otherwise, you can scan the QR code on your phone.
Now, the Twilio sandbox is set up, and it's configured so that you can try out your application after setting up the backend.
Before leaving the Twilio Console, you should take note of your Twilio credentials and edit the .env file as follows:
Setting up your Twilio WhatsApp API snippet
Before setting up the FastAPI endpoint to send a POST request to WhatsApp, let's build a utility script first to set up sending a WhatsApp message through the Twilio Messaging API.
Create a new file called utils.py and fill it with the following code:
First, the necessary libraries are imported, which include the following:
loggingfor logging messagestwilio, the Twilio REST client for sending WhatsApp messagesdecoupleto store private credentials in a .env filerequeststo send an HTTP GET request to the audio URLpydubfor audio file manipulation
Next, the Twilio Account SID, Auth Token, and phone number are retrieved from the .env file using the decouple library. The Account SID and Auth Token are required to authenticate your account with Twilio, while the phone number is the Twilio WhatsApp sandbox number.
Then, a logging configuration is set up for the function to log any info or errors related to sending messages. If you want more advanced logging to use as a boilerplate, check this out.
The first helper function of this utility script is the send_message function that takes two parameters, the to_number and body_text, which are the recipient's WhatsApp number and the message body text, respectively.
The function tries to send the message using the client.messages.create method, which takes the Twilio phone number as the sender (from_), the message body text (body), and the recipient's WhatsApp number (to). If the message is successfully sent, the function logs an info message with the recipient's number and the message body. If there is an error sending the message, the function logs an error message with the error message.
The ogg2mp3 function takes an OGG audio URL as input and downloads it, converts it to MP3 format using the Pydub library, and returns the path to the MP3 file. The logic inside is the same as discussed in the transcribe.py code except that it needs to fetch the audio URL first and then convert it.
The function starts with the requests library to send an HTTP GET request to the audio URL. You will need that because the WhatsApp voice note is sent as a Media URL through the Twilio API.
This URL redirects you to another URL, so the code then gets the redirect URL result from the response, which should be the actual URL of the audio file, using response.url. The urllib.request.urlretrieve() method is then used to download the OGG audio file and save it to your local machine.
Finally, it returns the absolute path of the converted MP3 file.
This function is an abstraction and you’ll use it in your FastAPI application to replace the audio_url input with the media URL sent to the Twilio response.
Setting up your FastAPI backend
To set up the FastAPI backend for the chatbot, navigate to the project directory and create a new file called main.py. Inside that file, you will set up a basic FastAPI application that will handle a single incoming request:
To run the app, run the following command:
Open your browser to http://localhost:8000. The result you should see is a JSON response of {"msg": "up & running"}.
However, since Twilio needs to send messages to your backend, you need to host your app on a public server. An easy way to do that is to use Ngrok.
If you're new to Ngrok, you can consult this blog post and create a new account.
Leave the FastAPI app running on port 8000, and run this ngrok command:
The above command sets up a connection between your local server running on port 8000 and a public domain created on the ngrok.io website. Once you have the Ngrok forwarding URL, any requests from a client to that URL will be automatically directed to your FastAPI backend.
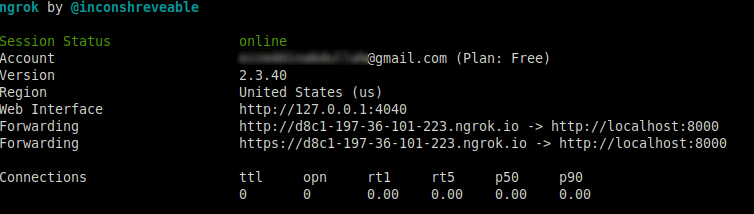
If you click on the forwarding URL, Ngrok will redirect you to your FastAPI app's index endpoint. It's recommended to use the https prefix when accessing the URL.
Configuring the Twilio webhook
You must set up a Twilio-approved webhook to be able to receive a response when you message the Twilio WhatsApp sandbox number.
To do that, head over to the Twilio Console and choose the Messaging tab on the left panel. Under the Try it out tab, click on Send a WhatsApp message. Next to the Sandbox tab, choose the Sandbox settings tab.
Copy the ngrok.io forwarding URL and append /message. Paste it into the box next to WHEN A MESSAGE COMES IN:
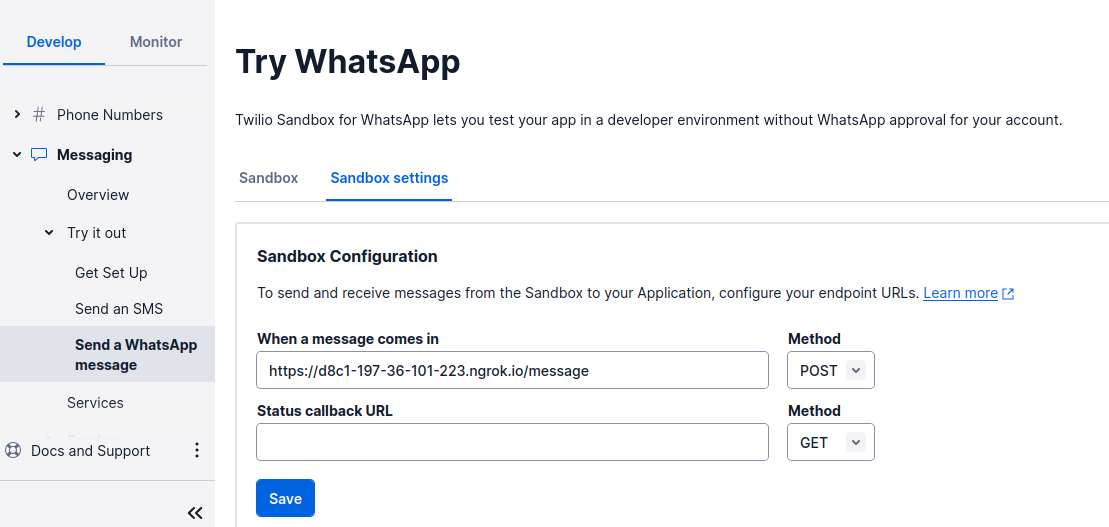
The complete URL should look like this: https://d8c1-197-36-101-223.ngrok.io/message.
The endpoint you will configure in the FastAPI application is /message, as noted. The chatbot logic will be on this endpoint.
When done, press the Save button.
Sending your message with OpenAI API
Now, it's time to create the logic for sending the WhatsApp message to the OpenAI API so that you'll get a response from the AI chatbot.
Update the main.py script to the following:
You've set up the /message endpoint so that the app will listen to the incoming POST requests to that endpoint, transcribe the voice note coming through the Whisper API, and generate a ChatGPT response to the transcribed text using the OpenAI API with GPT-3.5 model.
The code imports several third-party libraries, including openai, FastAPI, decouple, and SQLAlchemy. The Request class is imported from FastAPI for handling HTTP requests. It also imports objects from the two modules you defined in the same directory: models.py and utils.py.
A get_db() function is defined as a dependency using the Depends decorator from FastAPI. This function creates a new database session using the SessionLocal function from models.py and yields it to the calling function. Once the calling function completes, the database session is closed using the finally block.
The main function of the code is the reply() function, which is decorated with the @app.post('/message') decorator. This function takes in a message body as a parameter and a database session object obtained from the get_db() dependency.
Let’s break down what’s inside the reply() function here:
The audio file URL is extracted from the incoming message.
The audio file is downloaded and converted from OGG format to MP3 format using the ogg2mp3() function.
The MP3 file is transcribed using the OpenAI API with the whisper-1 model.
The transcribed text is sent to the OpenAI API with the gpt-3.5-turbo model to generate a response.
The function then attempts to store the conversation in a database by creating an instance of the Conversation class with the sender, message, and response as arguments. It adds this instance to the database session using the add method and commits the changes using the commit method. If an error occurs while storing the conversation in the database, such as an instance of the SQLAlchemyError class being raised, then the changes are rolled back using the rollback method and an error message is logged.
Finally, the function calls the send_message function with the phone number and ChatGPT response as arguments. It will send a return message to the original sender containing the ChatGPT response to the transcribed version of the voice note. The function then returns an empty string to the body of the Twilio response.
Testing your AI chatbot
Now, you're ready to send a WhatsApp voice note and wait for a response from your AI voice assistant. Try asking the AI chatbot anything you would ask an English teacher.
The example below shows a couple of questions and their responses:
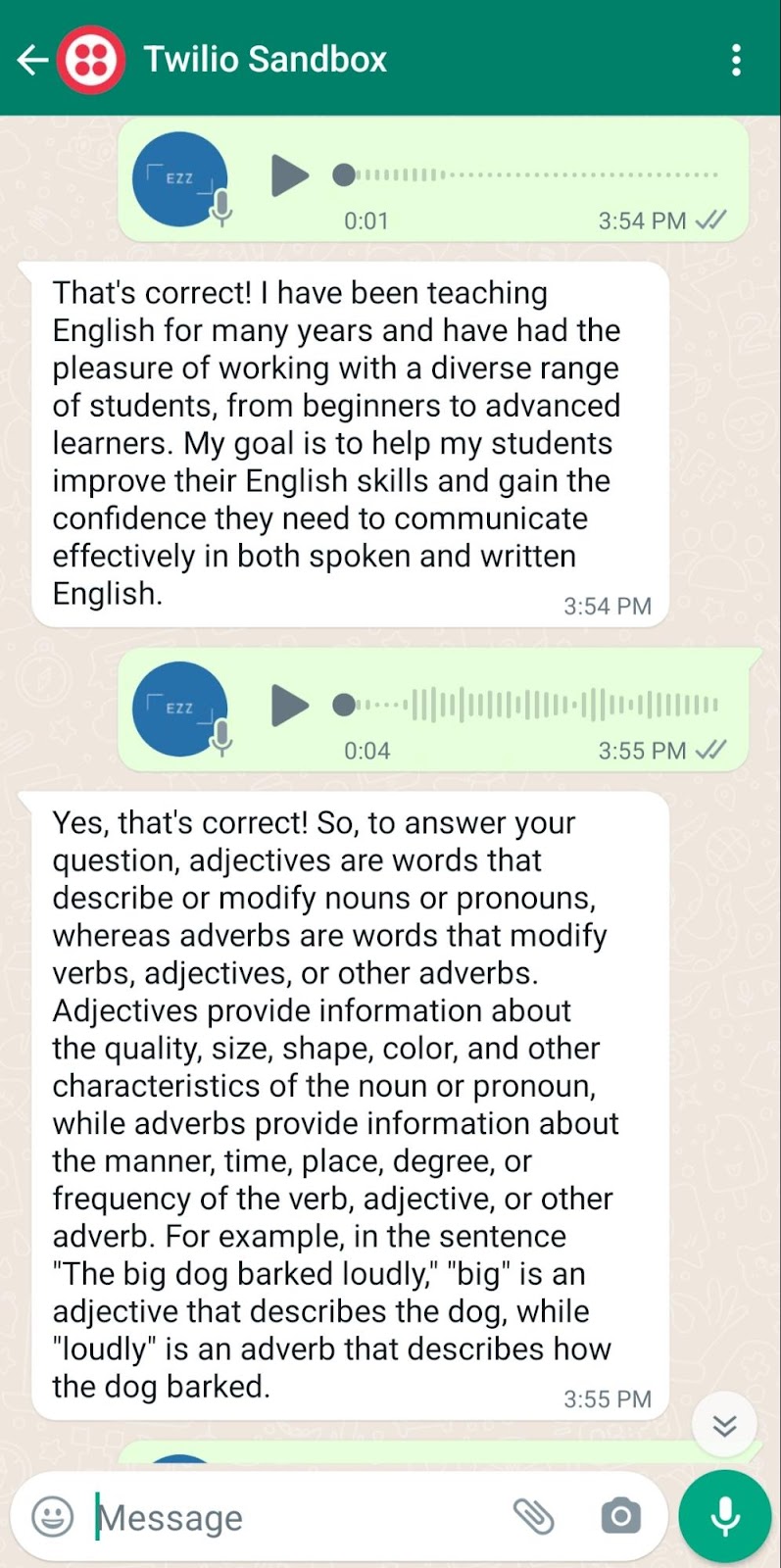
To interpret what I was actually saying, the first voice note was actually nothing, but Whisper transcribed it as the word “You”, and ChatGPT replied with a description about who the chatbot is.
The second voice note was me asking the chatbot about the difference between adjectives and adverbs. Whisper transcribed it correctly and the ChatGPT response was very relevant, and it also gave an example at the end to show the difference.
Now, your AI chatbot is functioning well on WhatsApp. Perhaps your next step is to make it live in production using a VPS instead of building it locally. I hope you enjoyed this tutorial and I’ll see you in the next one.
Ezz is a data platform engineer with expertise in building AI-powered chatbots. He has helped clients across a range of industries, including nutrition, to develop customized software solutions. Check out his website for more.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.